# 2020年12月技术日常
# 2020/12/25 周五
# 使用 Service Worker 接收服务器推送消息并显示通知
推送通知一般需要支持服务器推送,在常规网页中是不可能的。service worker 可以实现该行为
- service worker 可以显示通知
- service worker 可以处理这些通知的交互
- service worker 能够订阅服务器发送的推送通知
- service worker 能够处理推送消息,即使应用没有在前台运行或者根本没打开
1. 显示通知
在 service worker 中可以使用 ServcieWorkerRegistration 对象支持 showNotifications() 方法来显示通知,可以配置 title 和 options 配置
navigator.serviceWorker.register('./serviceWorker.js')
.then((registration) => {
Notification.requestPermission()
.then(status => {
if (status === 'granted') {
registration.showNotification('title')
}
})
})
在 serviceWorker.js 中使用 self.registration 也可以显示通知
// 注意 onactivate 默认只触发一次
self.onactivate = () => self.registration.showNotification('bar')
2. 处理通知事件
ServiceWorkerRegistration 对象创建的通知会向 service worker 发送 notificationclick 和 notificationclose 事件
self.onnotificationclick = (event) => {
// NotificationEvent {}, Notification {}
console.log('notification click', event, event.notification)
// 点击通知后,在新的 tab 打开网页
clients.openWindow('http://www.zuo11.com')
}
self.onnotificationclose = (event) => {
console.log('notification close', event, event.notification)
}
3.订阅推送事件
使用 registration.pushManager.subscribe() 可以对服务器推送消息发起订阅。注意这个过程中不会发送请求到我们的应用服务器。该函数包含两个参数:
userVisibleOnly通常被设置为 true,用来表示后续信息是否展示给用户。applicationServerKey秘钥,类型为 Uint8Array,用于加密服务端的推送信息,防止中间人攻击,会话被攻击者篡改。测试时,可以通过 web-push-codelab (opens new window) 网站获取秘钥并验证全流程,将该网站随机生产的 Application Server Keys 中的 Public Key 使用 urlBase64ToUint8Array() 转换后即可当做 applicationServerKey 使用
urlBase64ToUint8Array() 函数代码
function urlBase64ToUint8Array(base64String) {
const padding = '='.repeat((4 - base64String.length % 4) % 4);
const base64 = (base64String + padding)
.replace(/-/g, '+')
.replace(/_/g, '/');
const rawData = window.atob(base64);
const outputArray = new Uint8Array(rawData.length);
for (let i = 0; i < rawData.length; ++i) {
outputArray[i] = rawData.charCodeAt(i);
}
return outputArray;
}
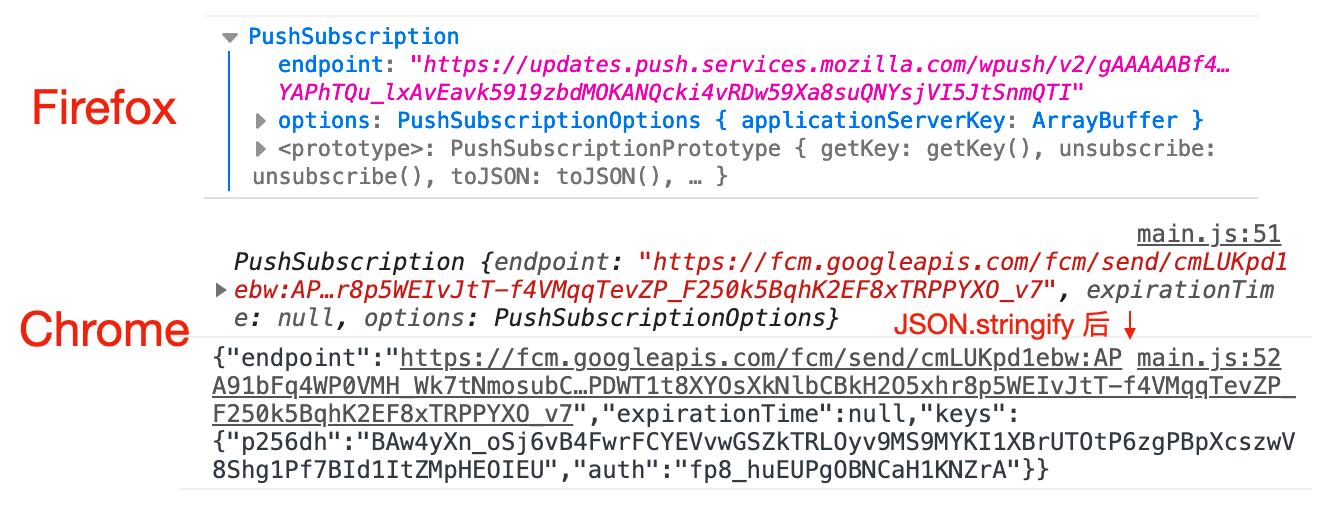
该函数返回一个 Promise,resolve 为 PushSubscription 对象,该对象包含服务器推送时必要的信息 不同的浏览器,对应的 endpoint 不一样。Chrome 和 Firefox 会不一样,如下图
WARNING
如果一直卡在 registration.pushManager.subscribe(),不向下执行,状态一直时 pending,可能是因为 Chrome 浏览器关于推送消息的功能,被墙了,需要翻墙才能正常返回
订阅代码如下:
// main.js
(async () => {
try {
const registration = await navigator.serviceWorker.register("sw.js");
const status = await Notification.requestPermission()
if (status === 'granted') {
const vapidPublicKey = 'BF9WWlvQiKSOwziO4gVeBdMeuhDW2HU2aCWAmaSLgXqGCGZK3ho15l30oQ6pdavh8acsc1kiXJNK-DtaqbHaZCQ';
const convertedVapidKey = urlBase64ToUint8Array(vapidPublicKey);
// 防止 DOMException: Failed to execute 'subscribe' on 'PushManager': Subscription failed - no active Service Worker
if (!registration.active) {
// 等待变为激活状态
await new Promise(r => setTimeout(r, 500))
}
const pushSubscription = await registration.pushManager.subscribe({
applicationServerKey: convertedVapidKey, // 来自服务器的公钥
userVisibleOnly: true
});
console.log(pushSubscription) // PushSubscription
console.log(JSON.stringify(pushSubscription)) // 这个消息可用于服务端发起推送
// {
// "endpoint": "https://fcm.googleapis.com/fcm/send/ecbqKLEnhB8:APA91bGvTW0x3k57bT9gDMLPPVkwLotGJyqJ1kk8yvNHyNAJ8Z0F6O74BuA8QxVNPIsgf1gWlGrUe0bYSs4L6fo-Fl18WkwGyHc3FEo2YvSUXBr5AA7KenaZBkL1D87WuAE7ERl-JCM4",
// "expirationTime": null,
// "keys": {
// "p256dh": "BIpKDNOPNQcBnfJVmdtZM2eJ0qS-FjicsiZK8jyUU07lGREwM_VZe2ulIWdrdlNlg7RFnHge8vJSe5y6TagW3Oc",
// "auth": "IlAite8VLBLWV5ubUXg91w"
// }
// }
}
} catch (err) {
console.log(err);
}
})()
上面的例子中,成功拿到 JSON.stringify(pushSubscription) 后,就可以在服务端使用该信息进行推送通知了。
4.处理服务端推送消息
// sw.js
// 当接收到服务端推送的消息时
self.onpush = pushEvent => {
// 服务器推送的消息文本
console.log(pushEvent.data.text())
// 保持 service worker 活动到显示通知 resolve
pushEvent.waitUntil(
// 将服务器推送的消息作为通知显示
self.registration.showNotification(pushEvent.data.text())
)
}
// 点击消息时
self.onnotificationclick = (event) => {
// NotificationEvent {}, Notification {}
console.log('notification click', event, event.notification)
// 点击通知后,在新的 tab 打开网页
clients.openWindow('http://www.zuo11.com')
}
现在来测试下,上面的例子中,我们使用 web-push-codelab (opens new window) 网站获取了 applicationServerKey 秘钥,我们同样可以在该网站发起服务端消息推送。将之前我们获取的 JSON.stringify(pushSubscription) 字符串拷贝到该网站的 Subscription to Send To 那一栏,然后在 Text to Send 中填写需要推送的消息。再点击 Send Push Message 按钮即可进行服务器推送。
这样就可以看到通知了。上面只是为了方便测试,如果需要使用程序化的方式来进行服务端推送,那就需要把 JSON.stringify(pushSubscription) 字符串传到后端,以 Node.js 为例,后端可以使用 web-push (opens new window) 来进行服务端推送。
参考:
- Service Worker学习与实践(三)——消息推送 - 知乎 (opens new window)
- Service Worker学习与实践(三)——消息推送 - CSDN (opens new window)
- Push API - W3C Editor's Draft 07 October 2020 (opens new window)
# 2020/12/24 周四
# Error: Timeout of 2000ms exceeded. Mocha 超时解决方法
在 mocha 中,默认每个测试时间限制为 2s,如果超过两秒就会抛出异常。对于大于 2s 的异步任务可以使用 mocha 上下文的 timeout() 方法手动指定超时时间。注意不要使用箭头函数,否则无法调用 this.timeout() 方法。
this.timeout(5000)将超时时间设置为 5s,这样就不会有 2s 的限制了this.timeout(1000)对于性能要求较高的场景,可以限制超时时间为 1s
// 耗时 3s 的异步任务
function asyncOptPromise() {
return new Promise((resolve, reject) => {
setTimeout(() => {
if (1 === 2) {
resolve()
} else {
reject('不相等') // 也可以是 reject(new Error('不相等'))
}
}, 3000)
})
}
describe('异步测试', function () {
it('asyncOpt 正确执行应该返回 true', async function() {
this.timeout(5000); // 设置超时时间为 5s
// this.timeout(1000);
await asyncOptPromise()
})
})
# 什么是 BDD 风格(BDD style)
should.js - BDD style shown throughout these docs
在 Mocha 官网的中,介绍 should.js 时,说它是一种 BDD 风格的断言库。而且在 mocha 的源码中,有很多都是以 bdd 命名的。那什么是 BDD 呢?
BDD 是 Behavior Driven Development 的简写,行为驱动开发,是在测试驱动开发(Test-Driven Development,TDD)基础上发展而来的一种软件开发方法。
TDD 测试驱动开发只关心代码要怎么写,有如下特点
- 写代码的时候要先写测试,反之测试不了的代码就不能写。测试是多种多样的,单元测试是最常见的,还有UI自动化测试
- 先写测试也有助于你理清代码的调用关系,写出来的逻辑更严谨
- 只要你写的每一次代码都有测试可以运行,那你的测试就非常全面了
BDD 行为驱动开发的本质在于 尽可能避免在需求描述、用例撰写、代码实现、测试等各环节衔接、转译过程中发生的信息丢失。和 TDD 不是一个概念。BDD使用 "用户故事" 来描述需求,然后开发人员将这些故事带入具体应用,通过不断迭代添加入真正的业务本质。
BDD 风格强调使用完整的、描述性的、便于业务用户理解的名称或术语,避免使用技术术语。BDD希望类、方法和变量的名称尽可能地反映日常用语。在编写单元测试的时候,尽量使用 BDD 风格为测试命名。
参考:
- 行为驱动开发BDD概要 - 没头脑的老毕 - 博客园 (opens new window)
- TDD 与 BDD 仅仅是语言描述上的区别么?- 知乎 (opens new window)
- 行为驱动开发(BDD) - HackerVirus - 博客园 (opens new window)
# 2020/12/13 周日
# HTTP 301 和 302 状态码的区别以及它们在浏览器和搜索引擎中的处理
301 和 302 状态码都是表示页面重定向,它们有两个用处:一是告诉浏览器,访问当前页面时需要跳转到新的页面。二是告诉搜索引擎如何正确的处理页面收录、索引。同样是发送 HTTP 请求,接收响应内容,浏览器对重定向页面的处理流程和普通页面有什么区别呢?一般访问某个页面时,基本流程如下:
客户端(浏览器)发起请求在浏览器中访问某个页面时,会向该页面资源所在的 URL 发送一个 HTTP 请求。服务端处理请求并响应服务器接收到请求后,会将资源的数据响应给前端,一般响应状态码 status 为 200,响应内容为 html 文本。客户端(浏览器)处理客户端接收到响应后,看状态码是否是 200 或 304(资源未修改),如果是就将浏览器返回的 html 内容解析、绘制在浏览器窗口中。
上面是简化版的普通页面打开流程,301 和 302 重定向的处理一般从第 2 步开始,服务器接收到请求后,我们需要自己加判断逻辑:
- 如果访问的 url 已失效,之后这个 url 可能会无法访问,需要跳转到新的 url,我们需要告诉浏览器我们的这种想法。可以将响应状态码设置为 301(Permanently Moved 永久性重定向
[ˈpɜːmənəntli]),并将 Location 响应头部设置为需要跳转的新 url。 - 如果访问的 url 没有失效,之后这个 url 还是可以访问,当前只是希望访问该 url 时临时跳转到一个新的 url。可以将响应状态码设置为 302(Temporarily Moved 临时性重定向
[ˈtemprərəli]),并将 Location 响应头部设置为需要跳转的新 url。
浏览器接收到响应后,当发现响应状态码 status 为 301 或 302 时,会将页面跳转(重定向)到 Location 响应头里设置的 url。下面是使用 koa 在服务端对 301 的实现,参考 nginx以及koa实现301跳转:xx.com重定向到www.xx.com - dev-zuo 技术日常 (opens new window)
const Koa = require('koa')
const app = new Koa()
app.use((ctx) => {
console.log(ctx.url)
if (ctx.url === '/test') {
// 当访问 /test 时 301重定向到 http://www.zuo11.com
ctx.status = 301
ctx.set({
'Location': 'http://www.zuo11.com'
})
return
}
// 非 /test 时,页面显示 welcome
ctx.body = 'welcome'
})
app.listen('9000', () => { console.log('服务已开启,9000端口') })
对浏览器来说,301 和 302 都是从一个 url 跳转到另一个新的 url,基本没啥区别。但对搜索引擎来说,如果是 301 永久性重定向,页面会删除失效的 url 收录、索引,并替换为新的 url。对于 302 的情况,搜索引擎会保留原 url 的收录和索引,并新增新 url 的收录、索引,这样更有利于页面的程序化处理。
# socket "Bad handshake method" 400
在使用 socket.io 测试 scoket 功能时,发现之前都运行正常的 demo 突然就无法正常运行了。接口返回 400 Bad Request,响应信息为 { code: 2, message: "Bad handshake method" }

后来发现是版本的问题,前端页面引入的 socket.io 版本是 2.3.0,通过 npm install 默认安装的 socket.io 版本是 3.0.4,将 koa 里面的 npm 包降到 2.3.0 就正常了
npm uninstall socket.io --save;
npm install socket.io@2.3.0 --save;
# performance.timing 页面各阶段耗时详解
performance.timing 记录了开始导航到当前页面的时间、浏览器开始请求页面的时间、浏览器成功连接到服务器的时间等。PerformanceTiming 类型。下面是按照顺序对各个字段的解释:
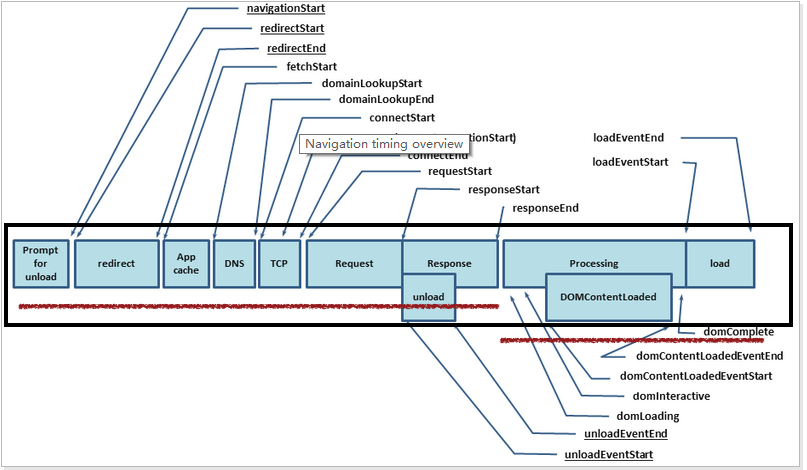
navigationStart: 1607492537332同一个浏览器上一个页面卸载结束时的时间戳。如果没有上一个页面的话,那么该值会和 fetchStart 的值相同。redirectStart: 0第一个 HTTP 重定向开始的时间戳。如果没有重定向,或者重定向到一个不同源的话,那么该值返回为 0。redirectEnd: 0最后一个 HTTP 重定向完成时的时间戳。如果没有重定向,或者重定向到一个不同的源,该值也返回为 0。fetchStart: 1607492537338浏览器准备好使用 http 请求的时间(发生在检查本地缓存之前)。domainLookupStart: 1607492537349DNS 域名查询开始的时间,如果使用了本地缓存(即无 DNS 查询)或持久连接,则与 fetchStart 值相等domainLookupEnd: 1607492537403DNS 域名查询结束的时间,如果使用了本地缓存(即无 DNS 查询)或持久连接,则与 fetchStart 值相等connectStart: 1607492537403HTTP(TCP)开始/重新 建立连接的时间,如果是持久连接,则与 fetchStart 值相等。secureConnectionStart: 1607492537472HTTPS 连接开始的时间,如果不是安全连接,则值为 0。connectEnd: 1607492537600HTTP(TCP) 完成建立连接的时间(完成握手),如果是持久连接,则与 fetchStart 值相等。requestStart: 1607492537601HTTP 请求读取真实文档开始的时间(完成建立连接),包括从本地读取缓存。responseStart: 1607492537841HTTP 开始接收响应的时间(获取到第一个字节),包括从本地读取缓存。responseEnd: 1607492537996HTTP 响应全部接收完成的时间(获取到最后一个字节),包括从本地读取缓存。unloadEventStart: 0前一个网页(和当前页面同域)unload的时间戳,如果没有前一个网页或前一个网页是不同的域的话,那么该值为0.unloadEventEnd: 0前一个页面 unload 时间绑定的回掉函数执行完毕的时间戳。domLoading: 1607492537852开始解析渲染 DOM 树的时间,此时 Document.readyState 变为 loading,并将抛出 readystatechange 相关事件。domInteractive: 1607492538002完成解析 DOM 树的时间,Document.readyState 变为 interactive,并将抛出 readystatechange 相关事件,注意只是 DOM 树解析完成,这时候并没有开始加载网页内的资源。domContentLoadedEventStart: 1607492538002DOM 解析完成后,网页内资源加载开始的时间,在 DOMContentLoaded 事件抛出前发生。domContentLoadedEventEnd: 1607492538002DOM 解析完成后,网页内资源加载完成的时间(如 JS 脚本加载执行完毕)。domComplete: 1607492544648DOM 树解析完成,且资源也准备就绪的时间,Document.readyState 变为 complete,并将抛出 readystatechange 相关事件。loadEventStart: 1607492544648load 事件发送给文档,也即 load 回调函数开始执行的时间。如果没有绑定load事件,该值为0.loadEventEnd: 1607492544653load 事件的回调函数执行完毕的时间。如果没有绑定load事件,该值为0.
function getPerfermanceTiming() {
let t = performance.timing
// 重定向结束时间 - 重定向开始时间
let redirect = t.redirectEnd - t.redirectStart
// DNS 查询开始时间 - fetech start 时间
let appCache = t.domainLookupStart - t.fetchStart
// DNS 查询结束时间 - DNS 查询开始时间
let dns = t.domainLookupEnd - t.domainLookupStart
// 完成 TCP 连接握手时间 - TCP 连接开始时间
let tcp = t.connectEnd - t.connectStart
// 从请求开始到接收到第一个响应字符的时间
let ttfb = t.responseStart - t.requestStart
// 资源下载时间,响应结束时间 - 响应开始时间
let contentDL = t.responseEnd - t.responseStart
// 从请求开始到响应结束的时间
let httpTotal = t.responseEnd - t.requestStart
// 从页面开始到 domContentLoadedEventEnd
let domContentloaded = t.domContentLoadedEventEnd - t.navigationStart
// 从页面开始到 loadEventEnd
let loaded = t.loadEventEnd - t.navigationStart
let result = [
{ key: "Redirect", desc: "网页重定向的耗时", value: redirect },
{ key: "AppCache", desc: "检查本地缓存的耗时", value: appCache },
{ key: "DNS", desc: "DNS查询的耗时", value: dns },
{ key: "TCP", desc: "TCP连接的耗时", value: tcp },
{ key: "Waiting(TTFB)", desc: "从客户端发起请求到接收到响应的时间 / Time To First Byte", value: ttfb },
{ key: "Content Download", desc: "下载服务端返回数据的时间", value: contentDL },
{ key: "HTTP Total Time", desc: "http请求总耗时", value: httpTotal },
{ key: "DOMContentLoaded", desc: "dom加载完成的时间", value: domContentloaded },
{ key: "Loaded", desc: "页面load的总耗时", value: loaded }
]
return result
}
getPerfermanceTiming()
参考:
- Web 性能优化-首屏和白屏时间 (opens new window)
- Performance --- 前端性能监控 (opens new window)
- 计时 API(Performace性能)- 20. JavaScript API - JS高程4笔记 (opens new window)
# node koa 怎么获取 POST 请求 Content-Type 为 "text/plain" 的数据
在 Beacon API 中,使用 navigator.sendBeacon(url, dataString) 发送的是 POST 请求,Content-Type 是比较少见的 "text/plain;charset=UTF-8" 。它既不是 xhr,也不是 fetch,是一种独立的请求类型。在 koa 中,一般使用 koa-bodyparser 来处理 post 请求数据。但这次发现使用 ctx.request.body 无法接收到数据。之前接收 "application/x-www-form-urlencoded" 和 "application/json" 类型的数据都是正常的。
查了下文档,发现 koa-bodyparser 默认情况下不支持解析 text/plain 类型的数据,需要设置可配置选项才行。
enableTypes: parser will only parse when request type hits enableTypes, support json/form/text/xml, default is ['json', 'form'].
app.use(require('koa-bodyparser')({
enableTypes: ['json', 'form', 'text']
}))
router.post('/user', async ctx => {
console.log(ctx.request.body)
// { page: '/xxx', duration: '12s' }
ctx.body = {
a: 1
}
})
其他 koa-bodyparser 需要注意的地方
- encoding: requested encoding. Default is utf-8 by co-body.
- formLimit: limit of the urlencoded body. If the body ends up being larger than this limit, a 413 error code is returned. Default is 56kb.
- jsonLimit: limit of the json body. Default is 1mb.
- textLimit: limit of the text body. Default is 1mb.
- xmlLimit: limit of the xml body. Default is 1mb.
参考
- post数据解析 koa-bodyparser (opens new window)
- Beacon API - 20. JavaScript API - JS高程4笔记 (opens new window)
# koa 使用 multer 处理文件上传,'multipart/form-data' 类型 FormData 数据解析
一般在 koa 中,post 请求的数据时需要中间件来处理的,koa-bodyparser 可以很好的处理 json、serializer 数据,但 multipart/form-data 的类型无法处理,一般需要引入另外的中间件来处理,一般建议使用 multer 中间件来处理。先来看看前端上传文件代码,这里使用的是 fetch,当然也可以使用 xhr
<!-- <input type="file" id="file"> -->
<input type="file" id="file" multiple>
<script>
let fileInput = document.getElementById('file')
fileInput.onchange = (event) => {
let formData = new FormData()
// 多个文件上传:使用同一个字段上传
console.log(event.target.files) // FileList 类数组对象
let files = event.target.files
for (let i = 0, len = files.length; i < len; i++) {
formData.append('image', files[i])
}
// 单文件上传
// formData.append('image', files[0])
formData.append('param1', 'abc')
fetch('/upload', {
method: 'POST',
body: formData
})
.then(console.log)
.catch(console.log)
// { param1: 'abc' }
}
</script>
可以看到在前端需要上传文件时,一般使用 FormData 类型数据。使用一个字段存放文件数据,上面例子中使用的是 "image" 字段。另外在上传文件时,额外添加了一个 param1 字段数据。下面来看看 multer 中间件是如何处理文件上传的,注意以下几点:
- 如果是单文件上传,使用
multer().single('文件字段')。ctx.file 可以拿到 file 对象 - 如果是多文件上传,使用
multer().fields([{ name: '文件字段', maxCount: '允许最大数'}])。ctx.files 可以拿到文件数据对象{ 字段1: [ file 数组], 字段2: [file 数组] } - 如果非文件上传,仅接收 FormData 类型的文本字段,使用
multer().none() - 普通 FormData 字段可以从 ctx.request.body 中获取
- file 对象包含如下属性
fieldname前端用于存放文件的字段名,这里例子中使用的是 'image'originalname文件名mimetype文件 MIMT 类型buffer文件二进制数据,可以直接使用fs.writeFileSync(文件名, buffer)创建文件size文件大小,单位字节
const multer = require('@koa/multer')
const fs = require('fs')
// 文件上传处理
// 前端 append 文件时使用的是 image 字段
let singleFileConfig = multer().single('image')
let multipleFilesConfig = multer().fields([
{
name: 'image',
maxCount: 5
}
])
let isMultiple = true
let fileConfig = isMultiple ? multipleFilesConfig : singleFileConfig
router.post('/upload', fileConfig ,async ctx => {
// 文件外的其他 FormData数据 { param1: 'abc' }
console.log('ctx.request.body', ctx.request.body)
console.log('ctx.files', ctx.files) // 多文件,返回 { 字段1: [file数组], 字段2: [file数组] }
console.log('ctx.file', ctx.file) // 单文件,返回 file 对象
// 如果是单文件取文件内容,如果是多文件,取第一个文件,前端字段传的 image
let file = isMultiple ? ctx.files['image'][0] : ctx.file
isMultiple && console.log(`ctx.files['image']`, ctx.files['image'][0])
// 在服务端本地创建文件
let { originalname, buffer } = file
fs.writeFileSync(originalname, buffer)
// {
// fieldname: 'image',
// originalname: '截屏2020-12-10 下午8.01.44.png',
// encoding: '7bit',
// mimetype: 'image/png',
// buffer: <Buffer 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 00 00 03 18 00 00 01 56 08 06 00 00 00 ea b0 3b 51 00 00 0c 64 69 43 43 50 49 43 43 20 50 72 6f 66 69 ... 90135 more bytes>,
// size: 90185
// }
ctx.body = ctx.request.body
})
完整测试代码,参见 fetch 上传文件 前端后代码 | Github (opens new window)
参考:
- express/multer 'multipart/form-data' | Github (opens new window)
- @koa/multer | Github (opens new window)
# 设置允许跨域的响应头后,为什么还是不能跨域
在 post 请求中,明明设置了允许跨域的响应头,且考虑了 preflight 预检请求,但为什么还是报不能跨域的错误呢?下面来看看下面的例子,POST 请求中设置了允许跨域、允许预检的响应头
router.post('/corsTest', ctx => {
// 以及允许跨域了
ctx.set({
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': '*',
'Access-Control-Allow-Headers': '*'
})
ctx.body = { a: 123 }
})
我们需要深入了解预检请求的过程,预检请求会先发送一个 OPTIONS 的请求去测试服务端是否允许跨域。这个时候我们需要注意,我们也需要处理对应接口的 OPTIONS 请求,上面只处理了接口 URL 的 POST 请求,并没有处理 OPTIONS 请求,可以使用 router.use(url, func) 或者加一个 router.options 请求处理
// options 预检请求时允许
router.options('/corsTest', ctx => {
ctx.set({
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': '*',
'Access-Control-Allow-Headers': '*'
})
ctx.body = {}
})
// 真实请求
router.post('/corsTest', ctx => {
ctx.set({
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': '*',
'Access-Control-Allow-Headers': '*'
})
ctx.body = { a: 123 }
})
关于请求预检的更多信息参见:CORS跨域资源共享 - 利用koa来彻底理解web前端跨域问题 - dev-zuo 技术日常 (opens new window)
# 2020/12/12 周六
# HTMLCollection 和 NodeList 有什么区别
在获取 dom 节点结集合时,有的 API 返回的是 HTMLCollection 类型,有的是 NodeList 类型。他们有什么区别呢?下来看看具体的 API
返回 HTMLCollection 类型的 API
- element.children 获取 element 元素的所有子元素节点
- document.getElementsByTagName('div')
- document.getElementsByName('kk')
- document.getElementsByClassName('kk')
- document.anchors 获取文档中所有带 name 特性的 a 元素,必须要有 name 属性
- document.forms 相当于 document.getElementsByTagName('form')
- document.images 相当于 document.getElementsByTageName('img')
- document.links 获取所有a元素,相当于 documet.getElmentsByTagName('a')
- form.elements 表单 form 元素的所有表单字段元素
返回 NodeList 类型的 API
- element.childNodes 获取元素所有子节点(包含元素节点、文本节点、注释节点等)
- document.querySelectorAll('div')
HTMLCollection 和 NodeList 的相同点:
- 它们都是表示节点集合的类数组对象,都可以是活动对象(实时监听 dom 变化并修改值)
- 它们都有 length 属性,都可以通过 item() 和数组下标的方式访问内部元素。都实现了 Symbol.iterator 迭代器方法(可以被 for...of 遍历)
HTMLCollection 和 NodeList 的不同点:
- HTMLCollection 中的值都是 Element 元素节点类型,NodeList 中的值是 Node 节点类型,可以是 Element 元素节点,也可以是 文本节点、注释节点等
- HTMLCollection 支持但 NodeList 不支持的方法:namedItem() - 通过 name 属性查找元素。NodeList 支持但 HTMLCollection 不支持的方法 keys(), values(), entries(), forEach()
关于 document.querySelectorAll() 函数的特殊情况,理论上该函数获取的是元素集合,可以使用 HTMLCollection,但为什么使用了 NodeList 呢?来看下面的例子
a = document.querySelectorAll('div')
b = document.getElementsByTagName('div')
console.log(a.length, b.length) // 75 75
document.body.appendChild(document.createElement('div'))
console.log(a.length, b.length) // 75 76
console.log(document.querySelectorAll('div').length) // 76
console.log(document.getElementsByTagName('div').length) // 76
上面的例子中 getElementsByTagName 获取的 HTMLCollection 类型的集合是实时的,动态的。而 querySelectorAll 获取的 NodeList 是非实时的,是静态的。
我的理解是,HTMLCollection 可能不支持创建静态副本。而 NodeList 可以是动态的活动对象,比如 element.childNodes,也可以是静态的,比如 querySelectorAll() 返回值。
参考:
- querySelectorAll() - Selectors API - 15. DOM 扩展 - JS高程4 (opens new window)
- HTMLCollection与NodeList - Segmentfault (opens new window)
# element.childNodes 和 element.children 有什么区别
元素的 childNodes 和 children 属性都是用于获取元素子节点,他们返回值都是类数组对象,且都是活动对象(当节点变更后,值也会动态变更)。但有以下区别:
- childNodes 获取的子节点包含所有节点类型,比如注释节点、文本节点、换行空白符文本节点,而 children 仅包含元素类型的子节点。
- childNodes 类型是 NodeList,children 类型是 HTMLCollection
有了 childNodes 为什么又出了 children 这个 DOM 专有扩展?children 属性是因为 IE9 之前的版本与其他浏览器在处理空白文本节点上有差异才出现的。参见 《JavaScript 高级程序设计(第 4 版)》第 15 章 DOM 扩展 - 专有扩展 - children 属性 p456
(function() {
let testDom = document.createElement('div')
testDom.innerHTML = `
123
<!-- sdfsdf -->
<span>abc</span>
<div>test</div>
`
let { childNodes, children } = testDom
console.log(childNodes) // NodeList(7) [text, comment, text, span, text, div, text]
console.log(children) // HTMLCollection(2) [span, div]
// 再次向节点追加内容,再打印之前获取的值
testDom.appendChild(document.createElement('div'))
console.log(childNodes) // NodeList(8) [text, comment, text, span, text, div, text, div]
console.log(children) // HTMLCollection(3) [span, div, div]
})()