# 20. JavaScript API
HTML5 规范定义了一批增强已有标准的 API 和浏览器特性。另外一些规范,如 Web Cryptography 和 Notifications API 只为一个特性定义了一个 API。不同的浏览器对新 API 的实现情况不同,本章仅介绍与大多数开发者相关,已经得到多个浏览器支持,且本书中其他章节没有涵盖的内容。主要内容有 Atomics 与 SharedrrayBuffer、跨上下文消息、Encoding API、File API 与 Blob API、拖放、Notifications API、Page Visibility API、Streams API、计时 API、Web components、Web Cryptography API。
# Atomics 与 SharedrrayBuffer
Atomics API 是 ES2017 新增的 API。在 Web Worker 中,如果多个线程操作共享缓冲区(SharedArrayBuffer)时,就可能出现资源争夺的问题,Atomics(原子操作)API 通过强制同一时刻只能对一个缓冲区执行一个操作,可以让多个上线文安全的读写一个 SharedArrayBuffer。
# SharedArrayBuffer
SharedArrayBuffer 与 ArrayBuffer 具有同样的 API,主要区别是 ArrayBuffer 只能被当前执行上下文使用。SharedArrayBuffer 可以被多个执行上下文同时使用。下面是 4 个专用工作者线程(Dedicated Workers)操作同一个 SharedArrayBuffer 的实例:
// main.js
// Create worker pool of size 4 创建包含 4 个线程的线程池
const workers = [];
for (let i = 0; i < 4; ++i) {
workers.push(new Worker('./worker.js'));
}
// Log the final value after the last worker completes
// 在最后一个 worker 完成后打印最终值
let responseCount = 0;
for (const worker of workers) {
worker.onmessage = () => {
if (++responseCount == workers.length) {
console.log(`Final buffer value: ${view[0]}`);
}
};
}
// Initialize the SharedArrayBuffer
const sharedArrayBuffer = new SharedArrayBuffer(4);
// 通过 typed array 向 sharedArrayBuffer 写入值 1
const view = new Uint32Array(sharedArrayBuffer);
view[0] = 1;
// Send the SharedArrayBuffer to each worker
for (const worker of workers) {
worker.postMessage(sharedArrayBuffer);
}
// 理论上值应该是 4000001,但实际是不超过 400万的数,而且还是动态的。
// (Expected result is 4000001. Actual output will be something like:)
// Final buffer value: 3254012
// worker.js
self.onmessage = ({data}) => {
const view = new Uint32Array(data);
// Perform 1000000 add operations 执行 100 万次加 1 操作
for (let i = 0; i < 1E6; ++i) {
view[0] += 1;
}
self.postMessage(null);
};
上面的例子中,每个工作者线程都顺序执行了 100 万次加操作,每次都是读取共享数组的索引,执行一次加操作,然后再把值写回索引。在线程并发执行时,可能会发生资源争用。例如
- 线程 A 读取到值 1
- 线程 B 读取到值 1
- 线程 A 加 1 并 将 2 写回数组
- 然后线程 A 用就的数据 1,同样把 2 写回数组
为了解决这个问题,可以使用 Atomics API,执行原子操作。view[0] += 1 改为 Atomics.add(view, 0, 1)。关于多个 Worker 操作 SharedArrayBuffer 可以参考 工作者线程数据传输 - 27. 工作者线程(Web Workers) (opens new window)
# 原子操作基础
任何全局上下文中都有 Atomics 对象,它包含了一些用于执行线程安全操作的静态方法,多数方法以一个 TypedArray 实例(一个 SharedArrayBuffer 的引用)为第一个参数,相关操作数为后续参数
算术以及位操作方法
Atomics.add(typedArray, index, 要加的数)对 typedArray index 索引值,执行原子加操作Atomics.sub(typedArray, index, 要减的数)对 typedArray index 索引值,执行原子减操作Atomics.or(typedArray, index, 要或的数)对 typedArray index 索引值,执行原子或操作Atomics.and(typedArray, index, 要与的数)对 typedArray index 索引值,执行原子与操作Atomics.xor(typedArray, index, 要异或的数)对 typedArray index 索引值,执行原子异或操作
// 创建一个字节的缓冲区,如果不清楚用法参考:6.集合引用类型 typed array
let sharedArrayBuffer = new SharedArrayBuffer(1)
// 基于缓冲区创建 类型数组 Uint8Array (另一种形式的 ArrayBuffer 视图)
let typedArray = new Uint8Array(sharedArrayBuffer)
// 默认 ArrayBuffer 里的值为 0
console.log(typedArray) // Uint8Array [0]
const index = 0,
num = 5;
// 执行原子加、减、或、与、异或操作
Atomics.add(typedArray, index, num)
typedArray // Uint8Array [5]
Atomics.sub(typedArray, index, num)
typedArray // Uint8Array [0]
Atomics.or(typedArray, index, 0b1111) // 十进制 15
typedArray // Uint8Array [15]
Atomics.and(typedArray, index, 0b1100)
typedArray // Uint8Array [12]
Atomics.xor(typedArray, index, 0b1111) // 相同为0,不同为1
typedArray // Uint8Array [3]
原子读和写 原子读和原子写之前或之后的非原子操作在执行时不会被重排,可以保证其执行顺序。
Atomics.load(typedArray, index)获取 typedArray index 索引处的值Atomics.store(typedArray, index, value)设置 typedArray index 索引处的值为 value
// 创建 4 个字节缓冲区
let sharedArrayBuffer = new SharedArrayBuffer(4)
let view = new Uint32Array(sharedArrayBuffer)
// 执行非原子写
view[0] = 1
// 非原子写可以保证在这个读操作之前完成,这里面一定读到的是 1
console.log(Atomics.load(view, 0))
// 执行原子写
Atomics.store(view, 0, 2)
// 非原子读,可以保证在原子写完成后执行,这里面一定督导的是 2
console.log(view[0]) // 2
原子交换,将缓冲区的值设置为新的值
Atomics.exchange(typedArray, index, newValue)原子交换,读取 typedArray index 索引的值,并将该缓冲区的值设置为 newValueAtomics.compareExchange(typedArray, index, oldView, newValue)有条件的原子交换,读取 typedArray index 索引的值,看是否与原缓冲区的值 oldView 一致,如果一致就写入新的值,否则不进行任何操作。
// 创建 4 个字节缓冲区
let sharedArrayBuffer = new SharedArrayBuffer(4)
let view = new Uint32Array(sharedArrayBuffer)
Atomics.store(view, 0, 2)
console.log(Atomics.exchange(view, 0, 5)) // 2
console.log(Atomics.load(view, 0)) // 5
let oldValue = Atomics.load(view, 0)
let newValue = oldValue ** 2
// 缓冲区的值未修改,还是 5,像缓冲区写入新值 25
Atomics.compareExchange(view, 0, oldValue, newValue)
console.log(Atomics.load(view, 0)) // 25
// 缓冲区的值已修改,不会像缓冲区写入新值 3
Atomics.compareExchange(view, 0, 24, 3)
console.log(Atomics.load(view, 0)) // 25
原子 Futex(fase user-space mutex 快速用户空间互斥量)操作与加锁,为了支持更加复杂的需求。Atomics API 提供了模仿 Linux Futex的方法。注意:这些方法只能用于操作 Int32Array 视图,而且只能用在 Worker(工作者线程) 内部
Atomics.wait(typedArray, index, value[, timeout])当 typedArray 视图中 index 索引的值等于 value 时阻塞,停止向下执行,获得锁。直到被唤醒或超时,超时时间为 tiemout 单位毫秒。默认值为 InfinityAtomics.notify(typedArray, index, count)唤醒 typedArray 中 index 索引位置的阻塞队列,通知唤醒的线程数量由 count 指定,默认是 InfinityAtomics.isLockFree(n)基本不会用到,用于在高性能算法中确定是否有必要获取锁
const workerScript = `
self.onmessage = ({data}) => {
const view = new Int32Array(data)
console.log('等待获得锁')
Atomics.wait(view, 0, 0, 1E5)
console.log('获得锁')
Atomics.add(view, 0, 1)
console.log('释放锁')
// 只允许一个 Work 继续执行
Atomics.notify(view, 0, 1)
self.postMessage(null)
}
`
const workerScriptUrl = URL.createObjectURL(new Blob([workerScript]))
const workers = []
// 创建 4 个 Worker
for (let i =0; i < 4; i++) {
workers.push(new Worker(workerScriptUrl))
}
// 在最后一个 worker 完成后打印最终值
let responseCount = 0;
for (const worker of workers) {
worker.onmessage = () => {
if (++responseCount == workers.length) {
console.log(`Final buffer value: ${view[0]}`);
}
};
}
const sharedArrayBuffer = new SharedArrayBuffer(8)
const view = new Int32Array(sharedArrayBuffer)
// 将 sharedArrayBuffer 发送到每个工作者线程执行 +1 操作
for (const worker of workers) {
worker.postMessage(sharedArrayBuffer)
}
// 1s 后释放第一个锁
setTimeout(() => Atomics.notify(view, 0, 2), 1000)
执行结果
// 等待获得锁
// 等待获得锁
// 等待获得锁
// 等待获得锁
// 获得锁
// 释放锁
// 获得锁
// 释放锁
// 获得锁
// 释放锁
// 获得锁
// 释放锁
// Final buffer value: 4
# 跨上下文(文档)消息传送(XDM)
跨文档消息,也简称为 XDM(cross-document messaging),是一种在不同执行上下文(如不同的工作线程或与 iframe 内嵌页面)间传递信息的能力。这里主要介绍与 iframe 内嵌的页面通信,关于 Worker 线程之间的通信参考本书第 27 章 工作者线程相关内容。XDM 的核心是 postMessage() 函数与 message 事件。
awindow.postMessage(message, sourceURL)向 awindow 窗口发送 message 信息, 指定接收源为 sourceURL(可以用于限制接收窗口的源必须是 sourceURL)。也可以设置为 * ,不限制源,但一般不推荐这么做。message事件,在 postMessage 后,awindow 上会触发 message 事件。该事件处理的程序的 event 包含以下三个重要信息data作为第一个参数传给 postMessge() 的字符串 message,虽然有些浏览器可以使用 JSON 数据,但不是所有浏览器都兼容,对于 JSON 数据还是需要调用 JSON.stringify() 将其转换为字符串。origin发送消息的文档源,例如 "http://127.0.0.1"source发送信息的文档中 window 对象的代理,主要用于向源窗口 postMessage
通过 iframe 加载不同的域时,使用 XDM 可以很方便的通信。也可以用于同源页面之间通信。下面是同源页面通信的示例 demo
<!-- 主页面 xdm.html -->
从 iframe 页面接收的消息:<span id="msg"></span>
<p>下面是 iframe,内嵌 iframe.html 页面 </p>
<iframe src="iframe.html" width="300" height="300"></iframe>
<script>
window.onload = function() {
console.log('准备开始 postMessage')
// 2s 后向 iframe 页面发送消息
setTimeout(function () {
try {
let iframeWindow = frames[0]
// 等价于
// let iframeWindow = document.getElementsByTagName('iframe')[0].contentWindow
// iframeWindow.postMessage('1111', 'http://127.0.0.1')
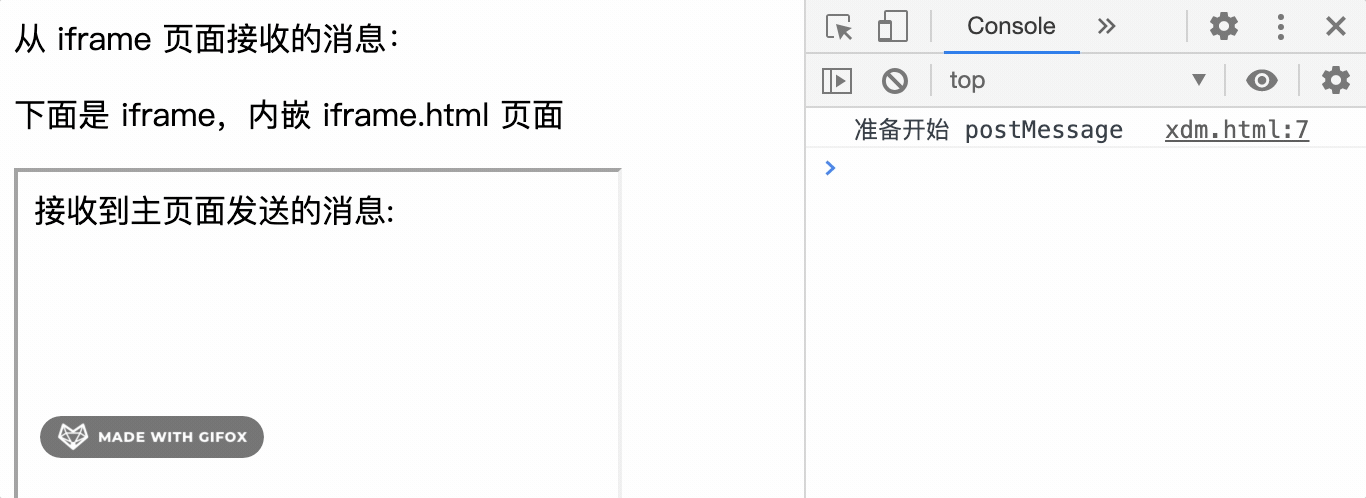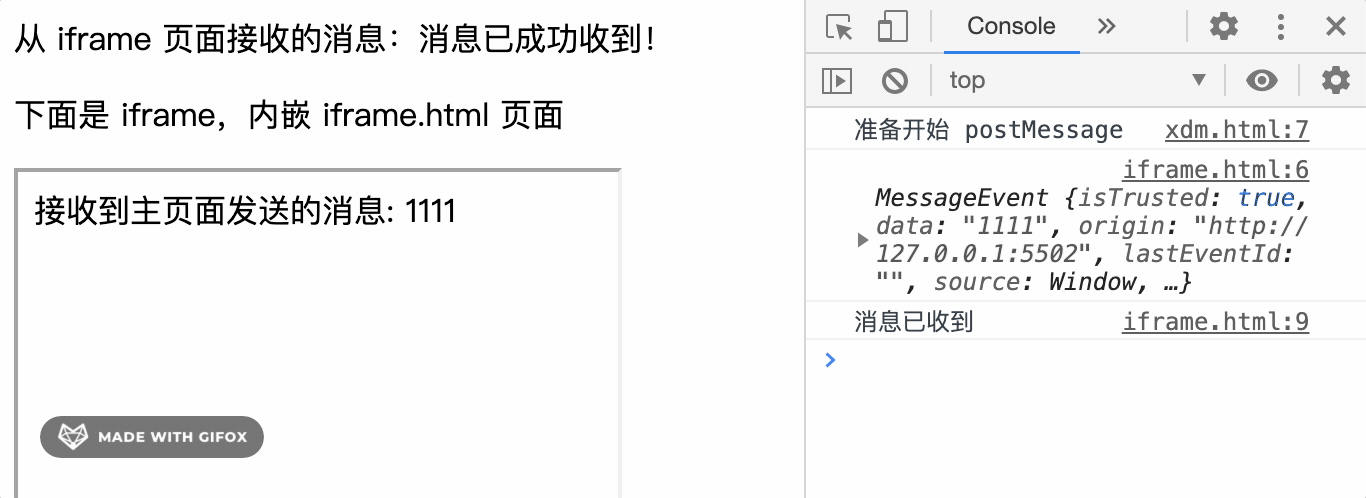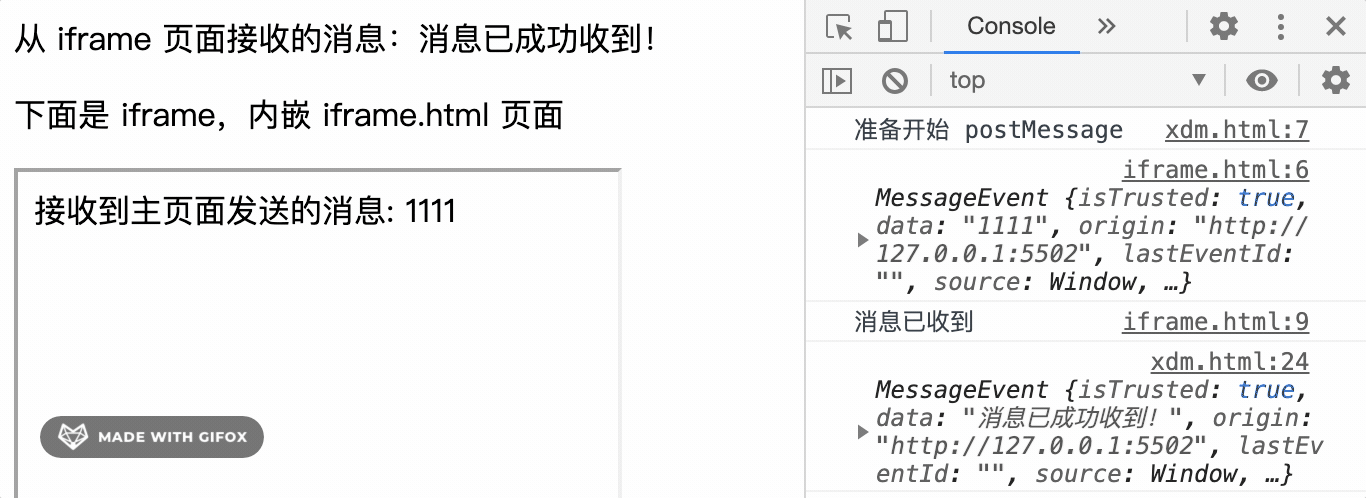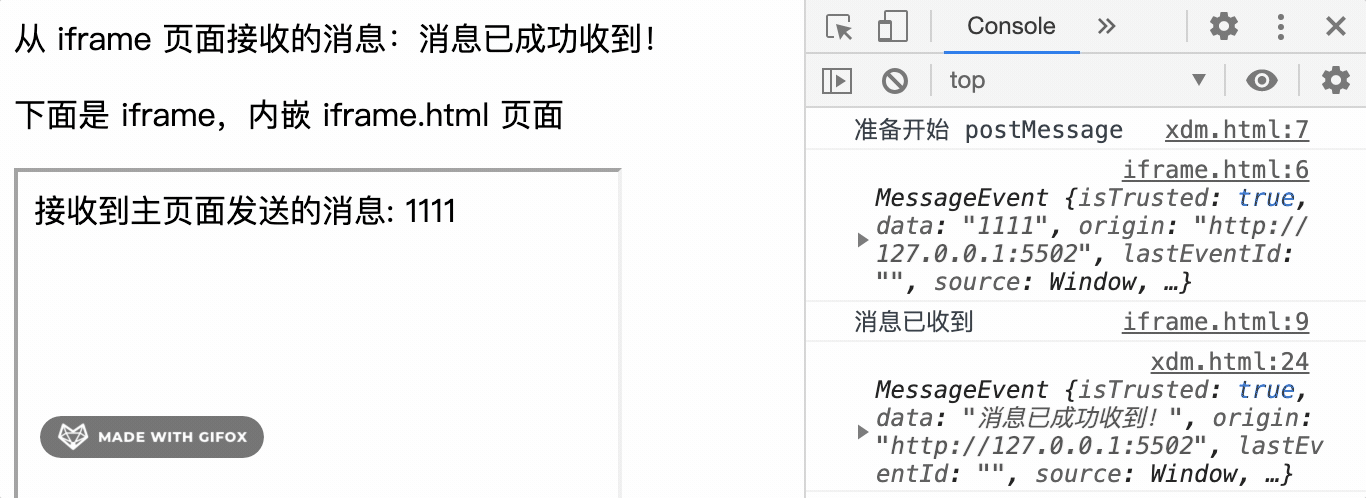
iframeWindow.postMessage('1111')
} catch(e) {
// 如果有加 http://127.0.0.1 限制接收源会报异常
// Failed to execute 'postMessage' on 'DOMWindow':
// The target origin provided ('http://127.0.0.1') does not match
// the recipient window's origin ('http://127.0.0.1:5502').
console.log(e)
}
}, 2000)
// 接收 iframe 窗口的消息并显示到 msg 位置
window.onmessage = function(event) {
var msg = document.getElementById('msg');
msg.innerHTML = event.data
console.log(event)
// { data: "消息已成功收到!", origin: "http://127.0.0.1:5502" }
}
}
</script>
iframe.html代码如下:
接收到主页面发送的消息: <span id="msg"></span>
<script>
window.onmessage = function(event) {
var msg = document.getElementById('msg');
msg.innerHTML = event.data
console.log(event)
// event.source.postMessage('消息已成功收到!', 'http://127.0.0.1/xdm/iframe.html')
event.source.postMessage('消息已成功收到!')
console.log('消息已收到')
}
</script>
运行效果如下
# Streams API
由于 Encoding API 涉及到流,这里将流的内容放到前面
Streams API 用于处理有序的小信息块,主要有两个应用场景
- 大块数据可能不会立即可用,http 响应数据时是以连续信息包形式传输的,流式处理可以让数据一到达就能使用,而不用等所有数据都加载完毕。
- 大块数据可能需要分成小块来处理。视频处理、数据压缩等都可以分成小块进行处理,而不必等所有数据都在内存中时再处理。
Streams API 直接解决的问题是处理网络请求和读写磁盘,它定义了三种流
可读流 ReadableStream,通过公共接口读取数据块的流。数据在内部从底层源进入流,然后由消费者(consumer)处理可写流 WritableStream,通过公共接口写入数据块的流。生成者(producer)将数据写入流,数据在内部传入底层数据槽(sink)转换流 TransformStream,由两种流组成,可写流用于接收数据(可写端),可读流用于输出数据(可读端)。这两个流之间是转换程序(transformer),可以根据需要检查和修改流内容
块、内部队列和反压 流的基本单位是 块(chunk)。块可以是任意数据类型,但通常是 typedArray。块不是固定大小的,也不一定按固定时间到达。流都有入口和出口的概念,数据进出速率不同,可能会出现不匹配的情况。为此流平衡可能会出现三种情况
- 流出口处理数据的速度比入口提供数据的速度快,流出口经常空闲,只会浪费一点内存或计算资源,这种情况可以接受
- 流入和流出均衡,理想状态
- 流入口提供数据的速度比出口处理数据的速度快,这种不平衡,会导致在某个地方出现数据积压,流必须做处理
流不平衡是常见的问题,因此所有流都会为已进入流,但未离开流的块提供一个 内部队列。如果块入列速度快与出列速度,内部队列会不断增大。流不可能允许内部队列无限增大,因此流会使用 反压(backpressure) 通知流入口停止发送数据,知道队列大小降到某个阈值之下。排列策略定义了内部队列可以占用的最大内存(即高水位线 high water mark)。
# 可读流 ReadableStream
可读流是对底层数据源的封装。底层数据源可以将数据填充到流中,允许消费者通过流的公共接口读取数据。
一般通过可读流的控制器(controller)将数据传入可读流,它是一个 ReadableStreamDefaultController 实例。在创建 ReadableStream 实例时,通过在 start 函数参数中,使用 controller.enqueue(chunk) 可以将 chunk 数据传入可读流
const readableStream = new ReadableStream({
start(controller) {
console.log(controller)
// ReadableStreamDefaultController {desiredSize: 1}
// 每隔 1 s 将 1、2、3、4、5 这几个值依次传入可读流
let chunk = 1
let timer = setInterval(() => {
if (chunk === 6) {
clearInterval(timer)
}
controller.enqueue(chunk++)
}, 1000)
// 传入完成后 调动 close 方法
controller.close()
}
})
// ReadableStream {locked: false}
上面的代码将 5 个值加入了可读流(ReadableStream 实例)的队列,但没有把它从队列中读取出来。我们需要使用 ReadableStream 实例的 getReader() 方法获取可读流的读取器(默认的 reader),调用该方法后会返回一个 ReadableStreamDefaultReader 实例。此时 ReadableStream 实例的 locked 会设置为 true。保证只有这个读取器可以从流中读取值。
消费者使用 ReadableStreamDefaultReader 实例的 read() 方法可以读出队列的值,这个 read() 方法的行为类似迭代器的 next() 方法
let sleep = () => new Promise(r => setTimeout(r, 1000))
const readableStream = new ReadableStream({
async start(controller) {
console.log(controller)
// ReadableStreamDefaultController {desiredSize: 1}
// 每隔 1 s 将 1、2、3、4、5 这几个值依次传入可读流
let chunk = 1
while(chunk < 6) {
await sleep()
controller.enqueue(chunk++)
}
// 传入完成后 调动 close 方法
controller.close()
}
})
readableStream.locked // false
const readableStreamDefaultReader = readableStream.getReader()
readableStream.locked // true
// 读取读取器实例的值,消费者
while(1) {
const { value, done } = await readableStreamDefaultReader.read()
if (done) {
break
} else {
console.log(value)
}
}
// 每隔 1 s 依次打印 1 2 3 4 5
上面的例子中,我们使用了 sleep 函数,每隔 1s 向可读流队列加入值,书中使用了 Generator 加异步迭代(for await of)的方法,在第 3 章 ECMAScript 基本概念 Symbol 类型中,有讲异步迭代,如果忘了可以翻看对应位置的笔记。这里使用书中的方法来重构上面的写法
async function* ints() {
for (let i = 1; i < 6; i++) {
yield new Promise(r => setTimeout(r, 1000, i))
}
}
const readableStream = new ReadableStream({
async start(controller) {
console.log(controller)
// ReadableStreamDefaultController {desiredSize: 1}
// 每隔 1 s 将 1、2、3、4、5 这几个值依次传入可读流
for await (const chunk of ints()) {
controller.enqueue(chunk)
}
// 传入完成后 调动 close 方法
controller.close()
}
})
readableStream.locked // false
const readableStreamDefaultReader = readableStream.getReader()
readableStream.locked // true
// 读取读取器实例的值,消费者
while(1) {
const { value, done } = await readableStreamDefaultReader.read()
if (done) {
break
} else {
console.log(value)
}
}
// 每隔 1 s 依次打印 1 2 3 4 5
# 可写流 WritableStream
使用 WriteableStream 构造函数可以创建一个可写流,可以将数据写入该流,方法与 ReadableStream 类似,但有一些区别
const writableStream = new WritableStream({
write(value) {
console.log(value)
}
})
// WritableStream {locked: false}
writableStream.locked // false
const writableStreamDefaultWriter = writableStream.getWriter()
writableStream.locked // true
let sleep = () => new Promise(r => setTimeout(r, 1000))
let chunk = 1
// 生成者
while(chunk < 6) {
await sleep()
// 等待写入器可以写入值
await writableStreamDefaultWriter.ready
// 向写入器写入值
writableStreamDefaultWriter.write(chunk++)
}
// 将流关闭
writableStreamDefaultWriter.close()
# 转换流 TransformStream
转换流用于组合可读流和可写流。其构造函数为 TransformStream,数据块在两个流之间通过 transform() 方法完成。写入的流会通过 transform 函数处理后,再传给可读流
const { writable, readable } = new TransformStream({
transform(chunk, controller) {
controller.enqueue(chunk * 2)
}
})
console.log(writable, readable)
const writableStreamDefaultWriter = writable.getWriter();
const readableStreamDefaultReader = readable.getReader();
// 消费者
(async function() {
while(1) {
const { value, done } = await readableStreamDefaultReader.read()
if (done) {
break
} else {
console.log(value)
}
}
})();
// 生产者
(async function() {
let sleep = () => new Promise(r => setTimeout(r, 1000))
let chunk = 1
// 生成者
while(chunk < 6) {
await sleep()
// 等待写入器可以写入值
await writableStreamDefaultWriter.ready
// 向写入器写入值
writableStreamDefaultWriter.write(chunk++)
}
// 将流关闭
writableStreamDefaultWriter.close()
})();
// 每隔 1s 依次打印
// 2 4 6 8 10
# 通过管道连接流
流可以通过管道连接在一起,ReadableStream 的实例可以使用以下两种方法操作管道
readableStream.pipeThrough(transformStream)通过管道,将 readableStream 接入 transformStream。readableStream 先把自己的值传给 transformStream 内部的 writableStream,然后转换后的值又在新的 readableStream 上出现。readableStream.pipeTo(writableStream)通过管道,将 readableStream 连接到 writableStream。管道连接操作隐式从 readableStream 获取了一个读取器,并把产生的值填充到 writeableStream
将 readableStream 接入 transformStream 实例
let sleep = () => new Promise(r => setTimeout(r, 1000))
const readableStream = new ReadableStream({
async start(controller) {
let chunk = 1
while(chunk < 6) {
await sleep()
controller.enqueue(chunk++)
}
controller.close()
}
})
const transformStream = new TransformStream({
transform(chunk, controller) {
controller.enqueue(chunk * 2)
}
})
// TransformStream {readable: ReadableStream, writable: WritableStream}
// 通过管道连接流
const pipedStream = readableStream.pipeThrough(transformStream)
// 从管道连接流获取 reader
const pipedStreamDefaultReader = pipedStream.getReader();
// 消费者
(async function() {
while(1) {
const { value, done } = await pipedStreamDefaultReader.read()
if (done) {
break
} else {
console.log(value)
}
}
})();
// 每隔 1s 依次打印 2 4 6 8 10
将 readableStream 连接到 writableStream 实例:
let sleep = () => new Promise(r => setTimeout(r, 1000))
const readableStream = new ReadableStream({
async start(controller) {
let chunk = 1
while(chunk < 6) {
await sleep()
controller.enqueue(chunk++)
}
controller.close()
}
})
const writableStream = new WritableStream({
write(value) {
console.log(value)
}
})
const pipedStream = readableStream.pipeTo(writableStream)
// 每隔 1s 依次打印 1 2 3 4 5
# Encoding API
Encoding API 主要用于实现字符串与 typed array之间的转换。规范新增了 4 个用于执行转换的全局类 TextEncoder、TextEncoderStream、TextDecoder 和 TextDecoderStream
"编码" Encode 是将字符串转为 typedArray,"解码" Decode 是将 typedArray 转换为字符串。
# TextEncoder 与 TextDecoder
普通字符串编码(bulk 编码/批量编码)使用 TextEncoder 类,TextEncoder 实例支持如下方法:
textEncoder.encode(str)将字符串 str 转换为 Uint8Array 格式的 typed array。返回每个字符的 UTF-8 编码textEncoder.encodeInto(str, typedArray)将每个字符的 UTF-8 编码写入类型为 Uint8Array 的 typedArray。主要是可以指定类型数组(定型数组)长度,如果类型数组空间不够会提交终止,返回值是一个对象:{ read: 成功从源字符串读取的字符个数,written: 成功写入到目标 typedArray 的字符个数 }
const textEncoder = new TextEncoder()
let encodeText = textEncoder.encode('foo0')
// f 的 UTF-8 编码是 102 => 0x66,0 48 => 0x30
// encodeText Uint8Array(4) [102, 111, 111, 48]
// 有些字符可能会占用多个索引
textEncoder.encode('😊') // Uint8Array(4) [240, 159, 152, 138]
const aView = new Uint8Array(3)
const bView = new Uint8Array(1)
textEncoder.encodeInto('foo', aView) // { read: 3, written: 3 }
console.log(aView) // Uint8Array(3) [102, 111, 111]
textEncoder.encodeInto('foo', bView) // { read: 1, written: 1 }
console.log(bView) // Uint8Array(1) [102]
可以使用 TextDecoder 对 typedArray 进行解码,将其转换为字符串,TextDecoder 实例支持如下方法:
textDecoder.decode(typedArray)将 typedArray 转换为字符串,默认字符编码是 UTF-8。也可以解码 UTF-16 字符编码进行解码。解码器不关心传入的是那种 typedArray,只专心解码整个二进制表示。传入 Uint32Array 也可以解码。
const textDecoder = new TextDecoder()
// Uint8 1个字节 8 位 [0x66, 0x6F, 0x6F, 0x30]
let decodeText = textDecoder.decode(Uint8Array.of(102, 111, 111, 48))
// decodeText "foo0"
// Unit32 4个字节 32位 [0x0066, 0x006F, 0x006F, 0x0030]
textDecoder.decode(Uint32Array.of(102, 111, 111, 48))
// 返回 "foo0" 书中加了空格是错的
textDecoder.decode(Uint8Array.of(240, 159, 152, 138))
// "😊"
const utf16TextDecoder = new TextDecoder('utf-16')
utf16TextDecoder.decode(Uint16Array.of(102, 111, 111))
// "foo"
# TextEncoderStream 与 TextDecoderStream
流编码(stream 编码)使用 TextEncoderStream,它其实就是 TransformStream 形式的 TextEncoder,将可读流的内容连接到 TextEncoderStream 实例(类似于 TransformStream 实例),可读流的内容传给该实例的可写流,然后将内部 transform(编码) 后的值,再给到新的可读流。
// 先创建一个可读的流,内容分别是 f o o 0
let sleep = () => new Promise(r => setTimeout(r, 1000))
const readableStream = new ReadableStream({
async start(controller) {
let str = "foo0"
for (let i = 0, len = str.length; i < len; i++) {
await sleep()
controller.enqueue(str[i])
}
controller.close()
}
})
// 对流进行编码
const encodeTextStream = readableStream.pipeThrough(new TextEncoderStream());
const encodeTextStreamDefaultReader = encodeTextStream.getReader();
// 读取编码后的流
(async function() {
while(1) {
const { value, done } = await encodeTextStreamDefaultReader.read()
if (done) {
break
} else {
console.log(value)
}
}
})();
// 每隔 1s 依次打印
// Uint8Array [102]
// Uint8Array [111]
// Uint8Array [111]
// Uint8Array [48]
TextDecoderStream 流解码与流编码类似。文本解码器流能够识别分散在不同块上的字符。解码器流会保持块片段直到取得完整的字符。比如当解码笑脸符号时,它不会单独输出,而是一个完整的笑脸。
// 先创建一个可读的流,内容分别是 f o o 0
let sleep = () => new Promise(r => setTimeout(r, 1000))
const readableStream = new ReadableStream({
async start(controller) {
// let arr = [102, 111, 111, 48] // foo0
let arr = [240, 159, 152, 138] //
arr = arr.map(item => Uint8Array.of(item))
for (let i = 0, len = arr.length; i < len; i++) {
await sleep()
controller.enqueue(arr[i])
}
controller.close()
}
})
// 对流进行编码
const decodeTextStream = readableStream.pipeThrough(new TextDecoderStream());
const decodeTextStreamDefaultReader = decodeTextStream.getReader();
// 读取编码后的流
(async function() {
while(1) {
const { value, done } = await decodeTextStreamDefaultReader.read()
if (done) {
break
} else {
console.log(value)
}
}
})();
// 如果 arr = [102, 111, 111, 48]
// 每隔 1s 依次打印
// f
// o
// o
// 0
// 如果 arr = [240, 159, 152, 138]
// 5s 后打印 😊
文本解码器流经常和 fetch() 一起使用,因为响应体可以作为 ReadableStream 来处理,例如
// 访问 https://api.zuo11.com/ibd/fooddaily/info
// 打开 console,粘贴下面的代码并执行
const res = await fetch('https://api.zuo11.com/ibd/fooddaily/info')
// Response {
// type: "basic",
// status: 200,
// body: ReadableStream,
// headers: {}
// }
const stream = res.body.pipeThrough(new TextDecoderStream())
// ReadableStream {locked: false}
const decodedStream = stream.getReader();
let resData = '';
(async function() {
while(1) {
const { value, done } = await decodedStream.read()
if (done) {
console.log('resData', resData)
break
} else {
resData += value
console.log(value)
}
}
})();
// {"code":200,"msg":"成功","data":{"id":1,"auditMark":0}}
// resData {"code":200,"msg":"成功","data":{"id":1,"auditMark":0}}
# File API 与 Blob API
2000年以前,处理文件的唯一方式就是在表单中加入 <input type="file"> 字段。File API 和 Blob API 在表单中的文件输入字段的基础上,添加了一些直接访问文件的接口。HTML5 在 DOM 上为文件输入元素添加了一个 files 集合。通过文件输入字段选择一个或多个文件时,该元素 files 属性里会包含一组 File 对象,一个 File 对象对应着一个文件。每个 File 对象,都有下列只读属性:
- name 本地文件系统中的文件名
- size 文件的字节大小
- type 字符串,文件的 MIME 类型
- lastModifiedDate: 字符串,文件上一次被修改的时间
<input id="fileInput" type="file">
<input id="multipleFileInput" type="file" multiple="multiple">
<script>
let fileInput = document.getElementById('fileInput')
let multipleFileInput = document.getElementById('multipleFileInput')
// 文件内容改变时,显示文件信息
fileInput.addEventListener('change', fileChangeHandle, false)
multipleFileInput.addEventListener('change', fileChangeHandle, false)
function fileChangeHandle(event) {
let files = event.target.files
for (let i = files.length - 1; i >= 0; i--) {
let fileInfo = files[i] // File对象
console.log('name: ', fileInfo.name)
console.log('lastModified: ', new Date(fileInfo.lastModified).toLocaleString()) // timestamp
console.log('type: ', fileInfo.type)
console.log('size: ', fileInfo.size) // B 字节 /1000 kb
}
}
// name: 截屏2020-12-03 下午8.49.12.png
// lastModified: 2020/12/3 下午8:49:18
// type: image/png
// size: 93192
</script>
# FileReader 类型
FileReader 是一种异步文件的读取机制,可以把 FileReader 想象成 XMLHttpRequest,区别只是它读取的是文件系统,而不是远程服务器数据。FileReader 提供了如下方法,来读取文件中的数据
readAsText(file[, encoding])以纯文本形式读取文件,将读取到的文本保存在对应 FileReader 实例的 result 属性中。readAsDataURL(file)读取文件,将文件以数据 URI(base64 格式字符串)的形式保存在 result 属性中。readAsBinaryString(file)读取文件,并将每个字符的二进制数据保存在 result 属性中,字符串中的每个字符表示一字节。readAsArrayBuffer(file)读取文件,并将文件内容以 ArrayBuffer 的形式保存在 result 中。
这些操作都是异步的,每个 FileReader 实例都会发布几个事件,其中比较有用的三个事件时:
progress 事件,还有更多数据,每 50ms 触发一次,与 XHR 的 progress 事件具有相同的信息:lengthComputable、loaded、total,还可以读取 FileReader 实例的 result 属性error 事件,发生了错误,FileReader 的 error 属性时一个对象,它仅有一个 code 属性,这个错误码的值可能是:1 未找到文件 2 安全错误 3 读取被中断 4 文件不可读 5 编码错误。load 事件,读取完成,如果 error 事件被触发,不会触发 load 事件
<input type="file" id="inputFile">
<script>
let inputFile = document.getElementById('inputFile')
inputFile.addEventListener('change', (event) => {
let file = event.target.files[0]
// 读取文件
let reader = new FileReader();
// 如果是图片,直接获取数据 URI 直接显示, 如果是其他,直接读取文本
if (!file.type.includes('image')) {
reader.readAsText(file) // 读取文件为文本内容
} else {
reader.readAsDataURL(file) // 获取文件的 Base64 URI
}
reader.onerror = function() {
let errMsg = [null, '未找到文件', '安全性错误', '读取中断', '文件不可读', '编码错误']
let errCode = reader.error.code
console.log('读取文件错误, code: ' + errCode + ',错误提示: ' + errMsg[errCode])
}
reader.onprogress = function(e) {
// 文件读取中,大概 50ms 刷新一次
console.log(`加载进度 ${e.loaded} / ${e.total}`)
}
reader.onload = function(e) {
// 文件读取完成会存到 reader.result里面
console.log(reader.result)
}
})
</script>
# FileReaderSync 类型
FileReaderSync 是 FileReader 的同步版本,仅在 Worker 中可用。
<input type="file" id="inputFile">
<script>
let inputFile = document.getElementById('inputFile')
inputFile.addEventListener('change', (event) => {
let file = event.target.files[0]
// 新开一个 Worker 线程去处理
const worker = new Worker('worker.js')
// 将文件数据发送给 worker
worker.postMessage(file)
// 监听 worker 内部发送的信息
worker.onmessage = (msg) => {
console.log('接收到 worker 的值', msg)
// 接收到 worker 的值
// MessageEvent { data: "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAPQA…j1JhSFU",... }
}
})
</script>
worker.js 代码
// 当 worker 接收到 file 数据时
self.onmessage = ({data}) => {
// 同步读 file
const syncReader = new FileReaderSync()
const result = syncReader.readAsDataURL(data)
console.log(result)
// 将数据发给主线程
self.postMessage(result)
}
# Blob 读取部分文件内容
如果只想读取文件的一部分,而不是全部,可以使用 File 对象的 slice(起始字节,要读取的字节数) 方法。会返回一个 Blob 实例,Blob 是 File 的超类(父类)。blob 表示二进制大对象(binary large object) 是 JS 对不可修改二进制数据的封装类型。
console.log(File.__proto__ === Blob) // true
可以使用字符串数组、ArrayBuffers、ArrayBuffersViews、其他Blob实例来创建 Blob。它的构造函数可以接收一个 options 参数,并在其中指定 MIME 类型。
new Blob(contentArray[, options])创建一个 Blob 对象,内容是 contentArray 拼接的内容。options 是一个可选的对象,支持传入文件 MIME type。Blob 实例包含两个属性 size,表示数据大小(字节)。type 表示文件 MIME 类型。
console.log(new Blob(['foo'])) // Blob {size: 3, type: ""}
console.log(new Blob(['{"a": "b"}'], { type: "application/json"}))
// Blob {size: 10, type: "application/json"}
console.log(new Blob(['<p>Foo</p>', '<p>Bar</p>'], { type: "text/html"}))
// Blob {size: 20, type: "text/html"}
使用 slice() 切分文件,返回 blob 对象,使用 FileReader 读取,可以实现仅读取文件的部分内容。
<input type="file" id="file">
<script>
let fileInput = document.getElementById('file')
fileInput.onchange = function (e) {
let file = e.target.files[0]
let blob = file.slice(0, 32) // 只读取 32B(字节)的内容
console.log(blob) // Blob {size: 32, type: ""}
if (blob) {
let reader = new FileReader()
reader.readAsText(blob)
reader.onerror = function() {
console.log('读取文件错误, ' + reader.error.code)
}
reader.onload = function() {
console.log('读取文件成功,' + reader.result)
let div = document.createElement('div')
div.appendChild(document.createTextNode(reader.result))
document.body.appendChild(div);
}
reader.onprogress = function(e) {
console.log('读取中.....' + e.loaded + '/' + e.total)
}
} else {
alert('您的浏览器不支持blob.slice()')
}
}
</script>
# 对象 URL 与 Blob
对象 URL,也称为 Blob URL,引用保存在 File 或 Blob 中数据的 URL,它的优点是不必把文件内容读取到 JS 中也可以直接使用文件。创建对象 URL,可以使用 window.URL.createObjectURL() 方法并传入 File 或 Blob 对象。IE10+ 支持
window.URL.createObjectURL(File或Blob对象)创建对象 URL,返回一个 string 类型的 URLwindow.URL.revokeObjectURL(objectURL)释放对应对象 URL 的内存。 虽然页面卸载时会自动释放对象URL占用的内存,但如果不用了,还是建议手工释放,节约内存。
<input type="file" id="file">
<img src="" id="img">
<script>
var file = document.getElementById('file')
file.onchange = function (e) {
var myfile = this.files[0]
var img = document.getElementById('img')
var dataUrl = window.URL.createObjectURL(myfile)
console.log('dataURL: ' + dataUrl)
// dataURL: blob:http://localhost:63342/b42b5b0a-fef8-4cb2-b26d-1973517ac08a
img.src = dataUrl
setTimeout(function() {
window.URL.revokeObjectURL(dataUrl);
}, 3000)
}
</script>
对象 URL 以及 FileReader.prototype.readAsDataURL 虽然都可以用于预览图片,但是他们的区别是 readAsDataURL 返回的是文件的 URI, base64 格式。而 createObjectURL() 返回的是一个链接 URL。对于比较大的文件 base64 会卡,对象 URL 不会,详情参见:FileReader.readAsDataURL与URL.createObjectURL的区别 | dev-zuo 技术日常 (opens new window)
# 读取拖拽文件并上传
使用 H5 拖放 API,从桌面上把文件拖放到浏览器中会触发 drop 事件。在 event.dataTransger.files 中可以读取到放置的文件,与通过 type 为 file 的 input 获取的 File 一致
<head>
<style>
#dragDiv { width:300px;height: 150px;border:2px dashed #ccc; }
.draging { border:2px dashed red !important; }
</style>
</head>
<body>
<div>拖拽文件到下面的方框区域</div>
<div id="dragDiv"></div>
<script>
let dragDiv = document.getElementById('dragDiv')
dragDiv.ondragenter = function(e) {
// 当文件拖动到区域,设置red边框样式
dragDiv.className = "draging"
}
dragDiv.ondragover = function (e) {
e.preventDefault() // 取消默认行为,设置可拖放
}
dragDiv.ondrop = function (e) { // 有文件拖放触发
dragDiv.className = ""
e.preventDefault() // drop默认行为会打开新的窗口,取消默认行为
// 将文件用XHR上传操作
// 1. 准备数据
let files = e.dataTransfer.files
let data = new FormData()
let info = ''
for (let i = files.length - 1; i >= 0; i--) {
console.log(files[i])
data.append('file' + i, files[i])
info += `<div>文件名: ${files[i].name},文件类型: ${files[i].type}}</div>`
}
dragDiv.innerHTML = info
console.log(Object.fromEntries(data.entries()))
// 2. 开始上传
let xhr = new XMLHttpRequest()
xhr.open('post', '/fileupdate', true) // 异步发送请求
xhr.onload = function () {
if (xhr.status === 200) { // 请求成功
alert(xhr.responseText)
} else {
alert('请求异常', xhr.status)
}
}
xhr.send(data)
}
dragDiv.ondragleave = function (e) { // 文件移出
dragDiv.className = ""
}
</script>
</body>
# 媒体元素video/audio
HTML5新增了两个与媒体相关的标签,让开发人员不必依赖任何插件就能在网页中嵌入音频与视频内容。标签为video和audio,IE9+ 支持。视频支持格式video/mp4; video/ogg; video/webm; 音频支持格式 audio/mp4; audio/mpeg(mp3); audio/ogg; audio/wav;
- video 和 audio 一般需要手动点击才能自动播放,如果 video 元素加了 muted 无声,是可以自动播放的。使用 Audio 构造函数创建音频播放时,只有等用户在页面上做了交互操作,才能播放。否则会报错 Uncaught (in promise) DOMException: play() failed because the user didn't interact with the document first
- 一般只有在视频可以播放时才能通过 JS 获取到视频总时长
- 更多属性、事件参考 p628
下面来看 video 与 audio 元素的 demo
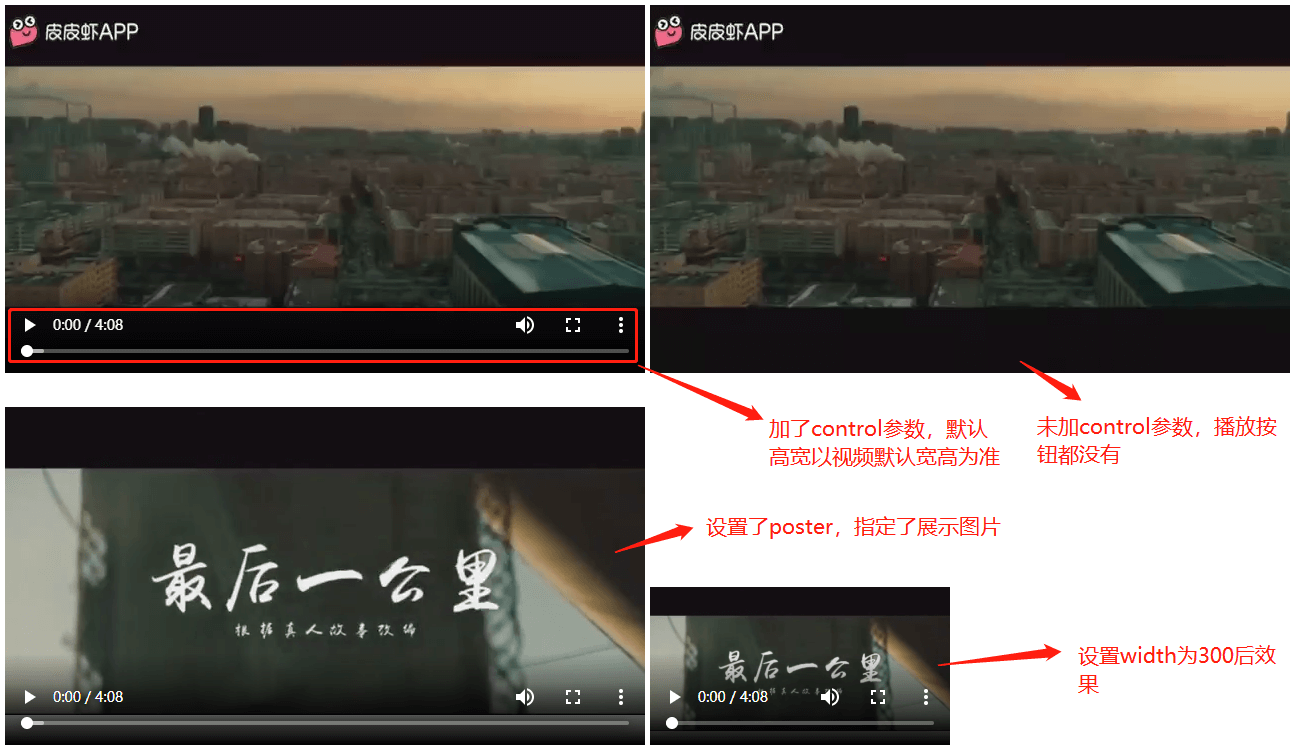
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>video</title>
</head>
<body>
<!-- 嵌入视频, 如果浏览器不支持会显示Video element not support -->
<video src="最后一公里.mp4" controls>Video element not support</video>
<video src="最后一公里.mp4">Video element not support</video>
<video id="video" src="最后一公里.mp4" controls poster="posterimg.png">Video element not support</video>
<video src="最后一公里.mp4" controls poster="posterimg.png" width="300">Video element not support</video>
<!--- 如果单独设置了autoplay,无法播放,需要再加一个muted属性才能自动播放,muted是让视频静音-->
<video src="最后一公里.mp4" controls poster="posterimg.png" width="300" autoplay muted>Video element not support</video>
<div>
<input type="button" onclick="play()" value="播放">
<input type="button" onclick="pause()" value="暂停">
<span id="curPlayTime"></span>/<span id="totalPlayTime"></span> 音量:<span id="volume"></span>
</div>
<script>
var video = document.getElementById('video')
// 无效
// setTimeout(function() {
// console.log(video)
// video.play()
// }, 5000)
// 需要点击事件才能触发,如果一进来直接调用函数会无效,除非播放时加入muted属性无声音。放在oncanplay里也无效
function play() {
console.log('video.play')
video.play()
}
function pause() {
console.log('video.pause')
video.pause()
}
var curPlayTimeEle = document.getElementById('curPlayTime');
var totalPlayTimeEle = document.getElementById('totalPlayTime');
var volumeEle = document.getElementById('volume');
// 只有在视频可以播放时才能获取到视频总时长
video.oncanplay = function() {
// video.play()
var duration = Math.ceil(video.duration)
totalPlayTimeEle.innerHTML = Math.floor(duration / 60) + '分' + duration % 60 + '秒';
console.log(video.duration);
}
// 更新当前播放时长及音量
setInterval(() => {
curPlayTimeEle.innerHTML = video.currentTime;
volumeEle.innerHTML = video.volume;
}, 250);
</script>
</body>
</html>
audio src 可以是声音,也可以是视频,如果是视频只会播放其声音
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>video</title>
</head>
<body>
<!-- 嵌入audio, 如果浏览器不支持会显示Video element not support -->
<p>播放mp4声音: 最后一公里.mp4</p>
<audio src="最后一公里.mp4" controls>audio element not support</audio>
<p>播放mp3声音: 王菲 - 匆匆那年.mp3</p>
<audio id="audio" src="王菲 - 匆匆那年.mp3" controls>audio element not support</audio>
<div>
<input type="button" onclick="play()" value="播放">
<input type="button" onclick="pause()" value="暂停">
</div>
<script>
var audio = document.getElementById('audio')
audio.oncanplaythrough = function() {
console.log('可以播放了')
// 这样也无效,还是要用按钮click触发
// chrome 和 firefox无效,IE11有效
// audio.play()
}
function play() {
console.log('audio.play')
audio.play()
}
function pause() {
console.log('audio.pause')
audio.pause()
}
</script>
</body>
</html>
素材及完整 demo 参见:video 与 audio demo | Github (opens new window)
# 指定多个媒体源/检测编解码器
由于浏览器支持的媒体格式不同,可以在 video 或 audio 元素内部使用 source 元素指定多个不同的媒体源,这时需要删除 src 属性。
<!-- 嵌入视频 -->
<video id="video">
<source src="a.webm" type="video/webm; codecs='vp8, vorbis'">
<source src="a.ogv" type="video/ogg; codecs='theora, vorbis'">
<source src="a.mpg">
不支持 video 功能
</video>
<!-- 嵌入音频 -->
<audio id="audio">
<source src="b.ogg" type="audio/ogg">
<source src="b.mp3" type="audio/mpeg">
不支持 audio 功能
</audio>
可以使用 audio 和 video 元素的 canplayType() 方法来检测浏览器是否支持给定格式和编解码器。它返回一个字符串:"probably", "maybe", ""
if (audio.canPlayType('audio/mpeg')) {
// 支持
}
# Audio 音频类型
使用 Audio 构造函数与 audio 元素类似。不需要插入 dom 即可工作。创建实例后,等下载完毕后就可以调用 play() 播放音频。但浏览器为了安全考虑,一般需要和页面有交互时,才可以播放音乐。在 iOS 中调用 play() 会弹出对话框,请求用户授权播放声音。为了连续播放,必须在 onfinish 事件处理程序中立即调用 play()
<div>123</div>
<script>
window.onload = () => {
let audio = new Audio('王菲 - 匆匆那年.mp3')
audio.addEventListener('canplaythrough', (event) => {
// 延时 3 s,中途点击页面,完成用 dom 交互
// Uncaught (in promise) DOMException: play() failed because the user didn't interact with the document first.
setTimeout(() => {
console.log('开始自动播放')
audio.play()
}, 3000)
})
}
</script>
# 原生拖放
该章节由于没有实例,且重要部分介绍内容有两处与实际不符,不好理解,不建议阅读本章来学习原生拖放
HTML标签 draggabl e属性,表示是否可拖动,img 和 a 标签、选中的文本默认为是可拖动的,其他元素默认为 false, 无法拖动。如果想让某个区域成为可放置区域,只需要将该区域 dragover 事件,阻止其默认行为
拖动某个元素时,会依次触发dragstart, drag, dragend 事件。当某个元素被拖动到一个有效的目标位置时,目标元素会依次触发dragenter, dragover,dragleave(不可放置)或drop(可放置)
参考: H5原生拖放(Drag and Drop)demo以及浏览器兼容性处理 | dev-zuo 技术日常 (opens new window)
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>drag demo</title>
<style>
.sec-content { width:600px;height: 400px;border:1px solid #ccc; }
.dragdiv {width:50px; height:50px;border:1px solid blue; margin-right:10px;}
.flexdiv { display: flex;}
#square1 { display: flex; flex-wrap: wrap}
</style>
</head>
<body>
<div>
<p class="sec-title">可拖动模块</p>
<div id="flexdiv" class="flexdiv">
<div id="dragdiv1" class="dragdiv" draggable="true">1</div>
<div id="dragdiv2" class="dragdiv" draggable="true">2</div>
<div id="dragdiv3"class="dragdiv" draggable="true">3</div>
<div id="dragdiv4" class="dragdiv" draggable="true">4</div>
</div>
</div>
<div>
<p class="sec-title">放置区域1</p>
<div id="square1" class="sec-content">
</div>
</div>
<script>
var flexdiv = document.getElementById('flexdiv');
flexdiv.addEventListener('dragstart', dragdivHandle, false);
flexdiv.addEventListener('drag', dragdivHandle, false);
flexdiv.addEventListener('dragend', dragdivHandle, false);
var square1 = document.getElementById('square1');
square1.addEventListener('dragenter', squareEventHandle, false);
square1.addEventListener('dragover', squareEventHandle, false);
square1.addEventListener('dragleave', squareEventHandle, false);
square1.addEventListener('drop', squareEventHandle, false);
function dragdivHandle(event) {
console.log(event.type)
switch(event.type) {
case 'dragstart':
// 针对拖动元素,设置event.effectAllowed
// event.dataTransfer.effectAllowed = 'copy'; // 这个设置与不设置貌似没什么作用
event.dataTransfer.setData('Text', event.target.id)
break;
}
}
function squareEventHandle(event) {
console.log(event.type)
switch(event.type) {
// case 'dragenter': // JS高程3里面p482内容: 如果想要让元素成为可放置区域,需要这里也阻止默认行为,但实际不用
// event.preventDefault();
// break;
case 'dragover':
event.preventDefault(); // 取消默认操作,可以让元素成为可放置区域
// 针对放置目标,设置event.dropEffect
// event.dataTransfer.dropEffect = 'copy'; // 这个设置与不设置貌似没什么作用
break;
case 'drop': // 该操作是动作执行的核心
// 防止火狐下,每次拖拽都会打开新的标签页
event.stopPropagation(); //阻止冒泡
event.preventDefault(); // 阻止默认事件
var id = event.dataTransfer.getData('Text');
console.log(id)
// 如果克隆了节点,不会删除源节点,如果通过getElementById获取对应的节点,会删除原来拖动的节点
// 如果是拖拽文件到该区域
console.log(event.dataTransfer.files); // 得到files数组,里面都是File文件对象
square1.appendChild(document.getElementById(id).cloneNode(true))
break;
}
}
</script>
</body>
</html>
# Notifications API
Notifications API 可以用于向用户发送通知。它在 Service Worker 中非常有用。PWA(Progressive Web Application 渐进式 Web应用)通过触发通知可以在页面不活跃时向用户显示消息,看起来就像原生应用。
通知权限需要用户授权,而且通知只能运行在安全上下文的代码中被触发,且必须按照每个源的原则,明确得到用户许可。可以使用下面的方法,触发用户授权
<script>
Notification.requestPermission().then((permission) => {
console.log('用户响应通知授权请求', permission)
})
</script>
第一次进入时,会有下面的弹窗提示。如果用户点击了运行,permission 的值为 granted,如果用户点击了禁止,返回 denied
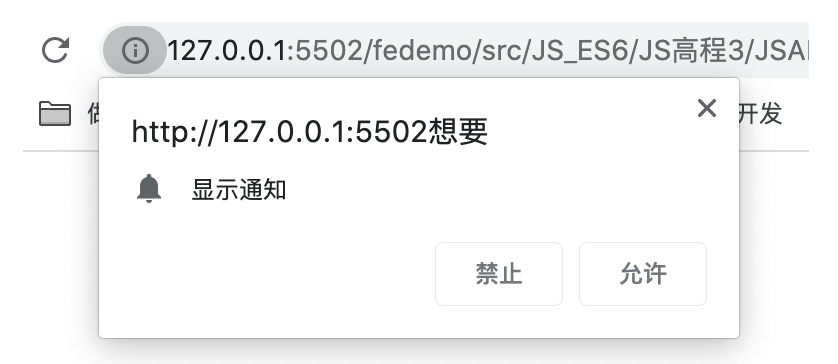
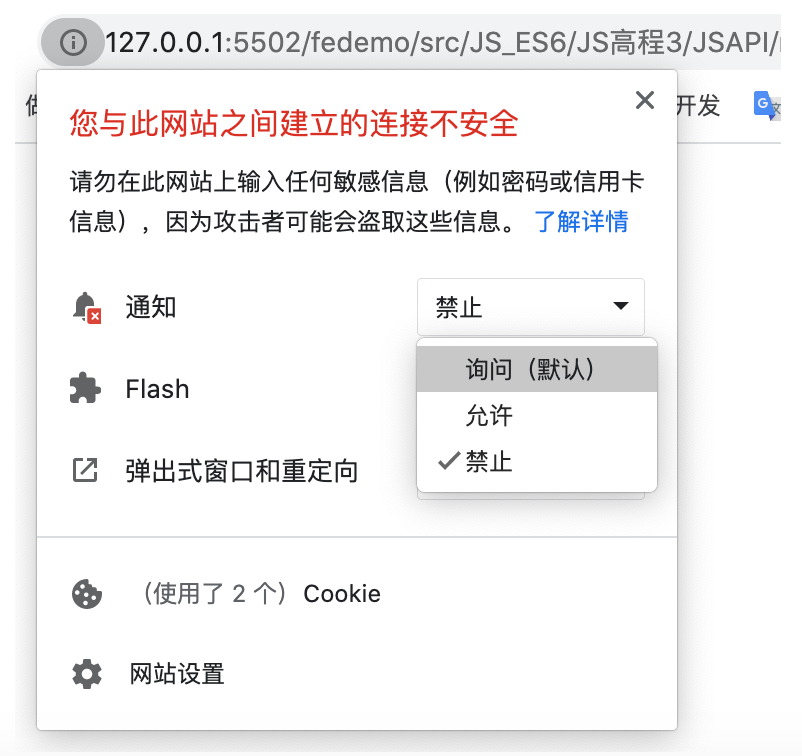
注意如果用户选择后,无法再通过代码的方式重新触发授权。只能手动设置浏览器,下图是 Chrome 浏览器设置的方法:点击页面 URL 前面的 信息 图标,会弹出一个下拉框。在通知那一栏,选择询问。再次调用上面的代码会重新触发通知授权。
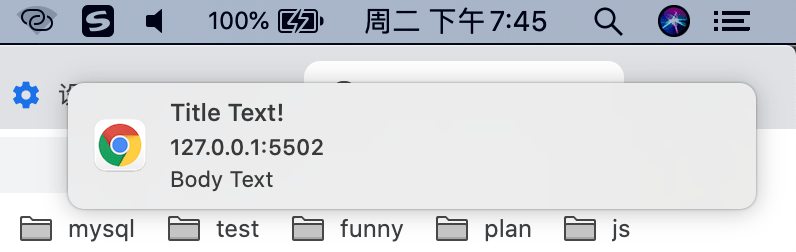
授权成功后的页面,调用 new Notification(title [, options]) 会立即发送通知
<script>
Notification.requestPermission().then((permission) => {
console.log('用户响应通知授权请求', permission)
if (permission === 'granted') {
new Notification('Title Text!', {
body: 'Body Text',
image: 'notification_1.png',
vibrate: true // 是否震动
})
}
})
</script>
效果如下图,默认 4-5 s 关闭,也可以通过 Notification 实例的 close() 方法手动关闭
通知不非只用于显示文本字符串,也可以用于交互,Notificaiton API 提供了 4 个用于添加回调的声明周期方法
onshow在通知显示时触发onclick在通知被点击是触发onclose在通知消失或通过 close() 关闭时触发onerror在发生错误阻止通知显示时触发
<script>
Notification.requestPermission().then((permission) => {
console.log('用户响应通知授权请求', permission)
if (permission === 'granted') {
let n = new Notification('Title Text!', {
body: 'Body Text',
image: 'notification_1.png',
vibrate: true // 是否震动
})
// 1s 后关闭通知
// setTimeout(() => n.close(), 1000)
n.onshow = () => console.log('notification show')
n.onclick = () => {
alert('onclick')
console.log('notification onclick')
}
n.onclose = () => console.log('notification close')
n.onerror = (e) => console.log('notification error', e)
}
})
</script>
# Page Visibility API(页面可见性API)
如果页面最小化了或者隐藏在了其他标签页面后面,有些功能可以停下来,比如轮询服务器或某些动画效果。而 Page Visibility API 就是为了让开发人员知道页面是否对用户可见而推出的。
document.hidden页面是否隐藏document.visibilityStateIE10 和 Chrome 对应的状态值有较大差异 IE 值为 document.MS_PAGE_HIDDEN(0) document.MS_PAGE_VISIBLE(1),chrome值为: hidden, visible, prerender(页面在屏外预渲染)visibilitychange 事件,当文档从可见变为不可见或从不可见变为可见时,触发该事件
// 实现tab间切换时,隐藏页面title改变功能
var title = document.title;
document.addEventListener('visibilitychange', function (event) {
console.log('--------------------')
console.log(event)
console.log(document.hidden)
console.log(document.visibilityState)
console.log('--------------------')
document.title = document.hidden ? '~ 你快回来 ~ ' : title
if (document.hidden) {
// 做一些暂停操作
} else {
// 开始操作
}
}, false)
# 计时 API(Performace性能)
Web Timing API,核心是 window.performance 对象。可以全面的了解页面再被加载到浏览器的过程中都经历了哪些阶段,页面哪些阶段可能是影响性能的瓶颈。部分功能 IE10+ 支持,部分不支持 IE,更多兼容性参考:Performance | MDN (opens new window)
Performance 接口由多个 API 组成
- High Resolution Time API,高精确度的时间 API,performance.now(),微秒精度。
- Performance Timeline API,性能条目(entry)时间轴 API,performace.getEntries()。按顺序记录页面加载过程中所有细节时间,包括导航时间、各资源加载时间(包括ajax请求)、渲染时间等,还可以自定义性能条目。
- Navigation Timing API,导航计时API,根据 performance.getEntriesByType('navigation') 获取 PerformanceNavigationTiming 对象,描述页面是何时以及如何加载的。
- User Timing API,用于自定义性能条目, performance.mark(), performance.measure()
- Resource Timing API,资源加载时间
- Paint Timing API, 渲染时间
# High Resolution Time API
High Resolution Time API 定义了 performance.now() 方法,返回一个微秒精度的浮点数。用以解决 Date.now() 毫秒级精度的一些缺陷。
performance.now()采用相对时间,在页面打开或执行上下文创建时,从 0 开始计时。performance.timeOriginperformance.now() 为 0 时,真实的时间戳
// 页面打开时间不到 1 秒时执行
performance.now() // 920.7399999722838
// 页面打开 5 秒后执行
performance.now() // 5289.069999940693
let relativeTime = performance.now()
// performance.now() 为 0 时的真实时间
performance.timeOrigin // 1607430305179.698
let realTime = performance.timeOrigin + relativeTime
new Date(realTime) // 当前时间
# performance.timing(扩展)
performance.timing 记录了开始导航到当前页面的时间、浏览器开始请求页面的时间、浏览器成功连接到服务器的时间等。PerformanceTiming 类型。下面是按照顺序对各个字段的解释:
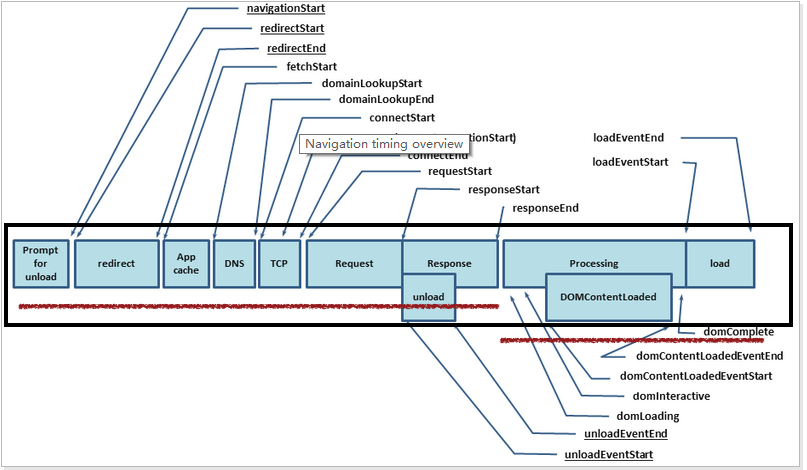
navigationStart: 1607492537332同一个浏览器上一个页面卸载结束时的时间戳。如果没有上一个页面的话,那么该值会和 fetchStart 的值相同。redirectStart: 0第一个 HTTP 重定向开始的时间戳。如果没有重定向,或者重定向到一个不同源的话,那么该值返回为 0。redirectEnd: 0最后一个 HTTP 重定向完成时的时间戳。如果没有重定向,或者重定向到一个不同的源,该值也返回为 0。fetchStart: 1607492537338浏览器准备好使用 http 请求的时间(发生在检查本地缓存之前)。domainLookupStart: 1607492537349DNS 域名查询开始的时间,如果使用了本地缓存(即无 DNS 查询)或持久连接,则与 fetchStart 值相等domainLookupEnd: 1607492537403DNS 域名查询结束的时间,如果使用了本地缓存(即无 DNS 查询)或持久连接,则与 fetchStart 值相等connectStart: 1607492537403HTTP(TCP)开始/重新 建立连接的时间,如果是持久连接,则与 fetchStart 值相等。secureConnectionStart: 1607492537472HTTPS 连接开始的时间,如果不是安全连接,则值为 0。connectEnd: 1607492537600HTTP(TCP) 完成建立连接的时间(完成握手),如果是持久连接,则与 fetchStart 值相等。requestStart: 1607492537601HTTP 请求读取真实文档开始的时间(完成建立连接),包括从本地读取缓存。responseStart: 1607492537841HTTP 开始接收响应的时间(获取到第一个字节),包括从本地读取缓存。responseEnd: 1607492537996HTTP 响应全部接收完成的时间(获取到最后一个字节),包括从本地读取缓存。unloadEventStart: 0前一个网页(和当前页面同域)unload的时间戳,如果没有前一个网页或前一个网页是不同的域的话,那么该值为0.unloadEventEnd: 0前一个页面 unload 时间绑定的回掉函数执行完毕的时间戳。domLoading: 1607492537852开始解析渲染 DOM 树的时间,此时 Document.readyState 变为 loading,并将抛出 readystatechange 相关事件。domInteractive: 1607492538002完成解析 DOM 树的时间,Document.readyState 变为 interactive,并将抛出 readystatechange 相关事件,注意只是 DOM 树解析完成,这时候并没有开始加载网页内的资源。domContentLoadedEventStart: 1607492538002DOM 解析完成后,网页内资源加载开始的时间,在 DOMContentLoaded 事件抛出前发生。domContentLoadedEventEnd: 1607492538002DOM 解析完成后,网页内资源加载完成的时间(如 JS 脚本加载执行完毕)。domComplete: 1607492544648DOM 树解析完成,且资源也准备就绪的时间,Document.readyState 变为 complete,并将抛出 readystatechange 相关事件。loadEventStart: 1607492544648load 事件发送给文档,也即 load 回调函数开始执行的时间。如果没有绑定load事件,该值为0.loadEventEnd: 1607492544653load 事件的回调函数执行完毕的时间。如果没有绑定load事件,该值为0.
function getPerfermanceTiming() {
let t = performance.timing
// 重定向结束时间 - 重定向开始时间
let redirect = t.redirectEnd - t.redirectStart
// DNS 查询开始时间 - fetech start 时间
let appCache = t.domainLookupStart - t.fetchStart
// DNS 查询结束时间 - DNS 查询开始时间
let dns = t.domainLookupEnd - t.domainLookupStart
// 完成 TCP 连接握手时间 - TCP 连接开始时间
let tcp = t.connectEnd - t.connectStart
// 从请求开始到接收到第一个响应字符的时间
let ttfb = t.responseStart - t.requestStart
// 资源下载时间,响应结束时间 - 响应开始时间
let contentDL = t.responseEnd - t.responseStart
// 从请求开始到响应结束的时间
let httpTotal = t.responseEnd - t.requestStart
// 从页面开始到 domContentLoadedEventEnd
let domContentloaded = t.domContentLoadedEventEnd - t.navigationStart
// 从页面开始到 loadEventEnd
let loaded = t.loadEventEnd - t.navigationStart
let result = [
{ key: "Redirect", desc: "网页重定向的耗时", value: redirect },
{ key: "AppCache", desc: "检查本地缓存的耗时", value: appCache },
{ key: "DNS", desc: "DNS查询的耗时", value: dns },
{ key: "TCP", desc: "TCP连接的耗时", value: tcp },
{ key: "Waiting(TTFB)", desc: "从客户端发起请求到接收到响应的时间 / Time To First Byte", value: ttfb },
{ key: "Content Download", desc: "下载服务端返回数据的时间", value: contentDL },
{ key: "HTTP Total Time", desc: "http请求总耗时", value: httpTotal },
{ key: "DOMContentLoaded", desc: "dom加载完成的时间", value: domContentloaded },
{ key: "Loaded", desc: "页面load的总耗时", value: loaded }
]
return result
}
getPerfermanceTiming()
参考:
# performance.navigation(扩展)
performance.navigation 记录了页面加载器重定向的次数,导航类型(页面第一次加载,页面重载过等状态)
redirectCount: 0页面经过了多少次重定向type: 0- 0 表示正常进入页面;"navigate"
- 1 表示通过 window.location.reload() 刷新页面;"reload"
- 2 表示通过浏览器前进后退进入页面;"back_forward"
- 255 表示其它方式 "TYPE_RESERVED"
# performance.memory(扩展)
MemoryInfo 记录了当前页面的内存信息
jsHeapSizeLimit: 4294,705,152内存大小限制,以字节计算。4G 电脑本身内存是 16GtotalJSHeapSize: 30,257,998可使用的内存,已分配的堆体积,示例中是 30M 左右,每个页面不一样,动态值usedJSHeapSize: 25,172,926JS 对象占用的内存,示例中是 25M 左右,每个页面不一样,动态值
# performance.eventCounts(扩展)
EventCounts 用于统计页面事件触发次数。每个页面都是 36 个事件,可以使用 performance.eventCounts.get('事件名称') 获取对应事件在页面中触发的次数。比如发生一次点击后,改之就会加 1。可以使用 forEach,entries 等遍历
performance.eventCounts // EventCounts {size: 36}
[...performance.eventCounts.entries()]
// [
// // ...
// ["click", 1]
// ["pointercancel", 0]
// ["dragover", 0]
// ["dragend", 0]
// ["beforeinput", 0]
// ["touchend", 0]
// ["compositionend", 0]
// ["mouseleave", 0]
// ["input", 0]
// ]
Object.fromEntries(performance.eventCounts.entries())
// {
// // ....
// auxclick: 0
// beforeinput: 0
// click: 4
// compositionend: 0
// compositionstart: 0
// compositionupdate: 0
// contextmenu: 0
// dblclick: 0
// }
# Performance Timeline API
性能时间轴 API,记录页面打开过程中,各个性能条目 (entry,如导航、资源加载、绘制等) 的耗时。使用 performance.getEntries() 可以获取所有性能条目信息数组。数组中的每一个元素代表一个性能条目,他们都是 PerformanceEntry 的子类,比如
- PerformanceNavigationTiming 导航时间对象,entryType: "navigation"
- PerformanceResourceTiming 某个资源加载时间对象,entryType: "resource"。发起者类型(资源类型)initiatorType: "script",还可能是:"xmlhttprequest"、"css"、"img"、"other"
- PerformancePaintTiming 绘制时间对象 entryType: "paint"
除了系统自带的这些性能条目外,还支持用户自定义性能条目
- PerformanceMark,用户自定义性能条目, entryType: "mark"
- PerformanceMeasure,性能度量条目, entryType: "measure"
可以使用 performance.getEntriesByType(entryType) 获取指定类型的性能条目,它返回一个数组
performance.getEntries()
// [
// PerformanceNavigationTiming,
// PerformanceResourceTiming,
// ...,
// PerformancePaintTiming,
// ...
// ]
# PerformanceNavigationTiming
一般 performance.getEntries() 的第一个元素就是 PerformanceNavigationTiming,浏览器会在导航事件发生时自动记录该性能条目。 duration = loadEventEnd - startTime
performance.getEntries()[0] // 或 performance.getEntriesByType('navigation')[0]
// PerformanceNavigationTiming
{
connectEnd: 2.0849999273195863
connectStart: 2.0849999273195863
decodedBodySize: 816
// domComplete: 9127.099999925122
// domContentLoadedEventEnd: 8586.609999998473
// domContentLoadedEventStart: 8586.6049999604
// domInteractive: 8586.544999969192
domainLookupEnd: 2.0849999273195863
domainLookupStart: 2.0849999273195863
duration: 9127.134999958798 // PerformanceNavigationTiming.loadEventEnd - PerformanceEntry.startTime
encodedBodySize: 816
entryType: "navigation" // 条目类型
fetchStart: 2.0849999273195863
initiatorType: "navigation" // 发起者类型
// loadEventEnd: 9127.134999958798 // load事件的回调函数执行完毕的时间,如果没有绑定load事件,该值为0.
// loadEventStart: 9127.124999999069 // load事件发送给文档。也即load回调函数开始执行的时间,如果没有绑定load事件,则该值为0.
name: "http://127.0.0.1:8080/js/ad3/js-ad3-20.html#high-resolution-time-api" // document's address.
nextHopProtocol: "http/1.1"
redirectCount: 0 // 如果有重定向的话,页面通过几次重定向跳转而来,默认为0;
redirectEnd: 0 //
redirectStart: 0 // 该值的含义是第一个http重定向开始的时间戳,如果没有重定向,或者重定向到一个不同源的话,那么该值返回为0.
requestStart: 10.624999995343387
responseEnd: 8198.495000018738
responseStart: 8198.014999972656
secureConnectionStart: 0
serverTiming: []
startTime: 0 // Returns a DOMHighResTimeStamp with a value of "0".
transferSize: 1100
type: "reload", // navigation type. Must be: 0: "navigate"(表示正常进入该页面(非刷新、非重定向)), 1: "reload"(表示通过 window.location.reload 刷新的页面。如果我现在刷新下页面后,再来看该值就变成1了), 2: "back_forward"(表示通过浏览器的前进、后退按钮进入的页面。如果我此时先前进下页面,再后退返回到该页面后,查看打印的值,发现变成2了) or "prerender" (其他).
// unloadEventEnd: 8201.974999974482
// unloadEventStart: 8201.824999996461
workerStart: 0
}
# PerformanceResourceTiming
计算某个资源的加载时间 duration = responseEnd - startTime
// performance.getEntriesByType('resource')[0]
connectEnd: 12499.234999995679
connectStart: 12499.234999995679
decodedBodySize: 4575838
domainLookupEnd: 12499.234999995679
domainLookupStart: 12499.234999995679
duration: 134.51500004157424 // responseEnd - startTime
encodedBodySize: 975116
entryType: "resource"
fetchStart: 12499.234999995679
initiatorType: "script"
name: "http://127.0.0.1:8080/assets/js/app.js"
nextHopProtocol: "http/1.1"
redirectEnd: 0
redirectStart: 0
requestStart: 12504.305000067689
responseEnd: 12633.750000037253
responseStart: 12512.550000101328
secureConnectionStart: 0
serverTiming: []
startTime: 12499.234999995679
transferSize: 975939
workerStart: 0
# User Timing API 自定义
performance.mark('foo') 可以在 performance.getEntries() 中新增一条自定义性能条目,可以用于自定义性能分析。
performance.mark('foo')
// PerformanceMark {
// detail: null,
// name: "foo",
// entryType: "mark",
// startTime: 39518.05999991484,
// duration: 0
// }
利用两个 mark 性能条目可以计算时间差
performance.mark('foo')
for (let i = 0; i < 1E6; i++) {}
performance.mark('bar')
let [startMark, endMark] = performance.getEntriesByType('mark')
endMark.startTime - startMark.startTime // 4.205000004731119
performance.measure() 可以生成一个新的性能条目,度量(计算) 两个 mark 之间的持续时间(duration)
performance.mark('foo')
for (let i = 0; i < 1E6; i++) {}
performance.mark('bar')
performance.measure('newVal', 'foo', 'bar')
// PerformanceMeasure {
// detail: null
// duration: 4.055000026710331
// entryType: "measure"
// name: "newVal"
// startTime: 2636.534999939613
// }
# Web 组件(Web Components)
这里所说的 Web Components 是一套用于增强 DOM 行为的功能,包括 影子 DOM(shadow DOM)、自定义元素 和 HTML 模板(template 元素),这一套浏览器 API 比较混乱:
- 并没有统一的 "Web Components" 规范,每个 Web Components 都在不同的规范中定义
- 有些 Web Components 如影子 DOM 和自定义元素,已经出现了向后不兼容的版本问题
- 浏览器实现极其不一致
由于存在上面的问题,一般使用 Web Components 时通常需要引入一个 Web 组件库,比如 Polymer,它可以模拟浏览器中缺失的 Web Components
# HTML 模板(template 元素)
在 Web Components 之前,一直缺少基于 HTML 解析构建 DOM 子树,然后在需要时把该子树渲染出来的机制。有两种替代的方法:
- 使用 innerHTML 把标记字符串转为 DOM 元素,但它存在严重的安全隐患。
- 使用 document.createElement 创建元素并拼接,这样非常麻烦
HTML 模板 template 元素就是为了解决这个问题而出现的,可以提前在页面中写出 template 内容,浏览器自动将其解析为 DOM 子树,但跳过渲染。等需要时,再渲染。
<template id="foo">
<p>模板内部p元素</p>
</template>
上面的例子中,使用 template 元素写了一个简单的模板,它的内容不属于活动的文档,内容不会渲染到页面上。使用 document.querySelector() 等 DOM 查询方法不会找到 p 元素,p 元素仅包含在 template 中的 DocumentFragment 内,审查元素时会看到下面的效果。可以通过 template 元素的 content 获取 DocumentFragment 节点的引用
<template id="foo">
#document-fragment
<p>模板内部p元素</p>
</template>
<script>
const fragment = document.querySelector("#foo").content
// #document-fragment
console.log( document.querySelector("p")) // null
console.log( fragment.querySelector("p")) // <p>...</p>
</script>
可以将 template 元素的内容,动态添加到 dom 中,仅一次重排。这就是 DocumentFragment 的优点
<div id="foo"></div>
<template id="bar">
<p>a</p>
<p>b</p>
<p>c</p>
</template>
<script>
// 将 template 元素的内容转移到 foo 元素内
const barTemplate = document.querySelector('#bar')
const fragment = barTemplate.content
const fooElement = document.querySelector('#foo')
// appendChild 会移动元素,之前的元素所在的位置会删除
fooElement.appendChild(fragment)
// 如果需要保留原元素,需要在 appendChild 时创建一个节点的副本
// fooElement.appendChild(document.importNode(fragment, true))
// fooElement.appendChild(fragment.cloneNode(true))
console.log(barTemplate.content.children) // HTMLCollection []
</script>
模板内也可以使用 script 脚本,最开始不会执行,等 template 内容添加到真实的 DOM 树中时才会执行
<div id="foo"></div>
<template id="bar">
<script>console.log('template script execute')</script>
</template>
<script>
let fragment = document.querySelector('#bar').content
console.log('a')
document.querySelector('#foo').appendChild(fragment)
console.log('b')
// a
// template script execute
// b
</script>
# 影子DOM(shadow DOM)
shadow DOM 是什么?HTML 元素调用 attachShadow() 方法,可以给自己添加一个影子DOM。该影子 dom 是一个独立的 DOM 子树,内部的 style 只会在该 影子 DOM 中有效,不干扰全局。默认情况下,影子 DOM 的内容会覆盖原 HTML 元素的内容。
注意:并不是所有的元素都可以添加影子 DOM,可以创建影子 DOM 的元素有 自定义元素、div、span、atricle、body 等,参见 p652
下面的例子中,为 foo 和 bar 元素添加影子 DOM 后,原内容 a、b 会被影子 DOM 覆盖,默认显示为空白,因为还没有向影子 DOM 添加任何内容。其中
- foo、bar 容纳影子 DOM 的元素被称为 影子宿主(shadow host)
- 影子 DOM 的根节点被称为 影子根(shadow root)
<div id="foo">a</div>
<div id="bar">b</div>
<script>
const foo = document.querySelector('#foo')
const bar = document.querySelector("#bar")
// 在 foo, bar 上创建影子 DOM,返回影子 dom 实例
const fooShadowDom = foo.attachShadow({ mode: "open"})
const barShadowDom = bar.attachShadow({ mode: "closed"})
console.log(fooShadowDom) // #shadow-root(open)
console.log(barShadowDom) // #shadow-root(closed)
console.log(foo.shadowRoot) // #shadow-root(open)
console.log(bar.shadowRoot) // null
</script>
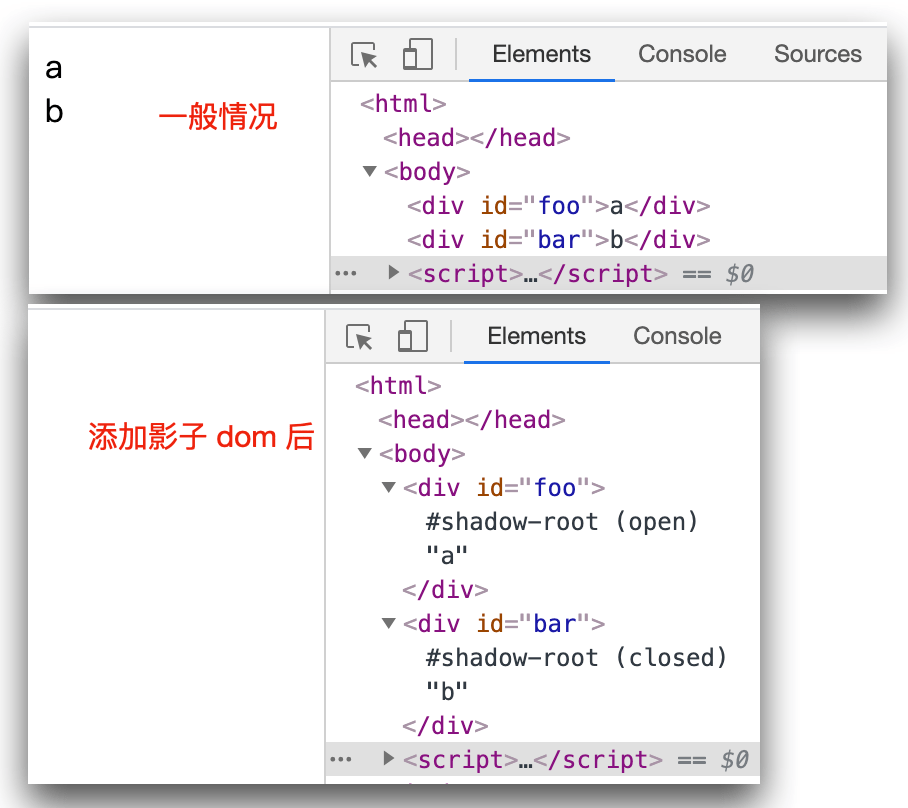
为元素添加影子 DOM 后,我们可以像常规 DOM 一样使用影子 DOM,来看下面的例子
fooShadowDom.innerHTML = `
<p>颜色:red</p>
<style>p { color: red; }</style>
`
barShadowDom.innerHTML = `
<p>颜色:green</p>
<style>p { color: green; }</style>
`
document.querySelectorAll('p') // 无法获取影子 dom 中的 p元素
// NodeList []
document.querySelectorAll('div')[0].shadowRoot
// #shadow-root (open)
// <p>颜色:red</p>
// <style>p { color: red; }</style>
效果如下
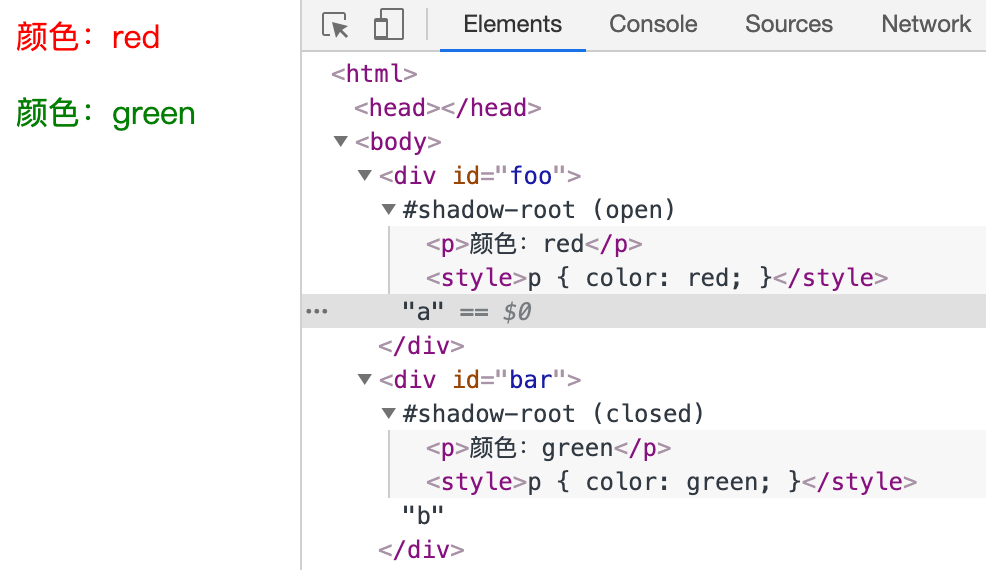
可以使用 appendChild() 向影子 DOM 中动态的添加元素,前面的例子中我们知道影子 DOM 会覆盖原元素的内容。如果我们想要在影子 DOM 中显示该内容,可以使用 slot 插槽元素来显示
<div id="foo">我是被隐藏的内容,在影子 DOM 中可以使用 slot 插槽来显示</div>
<script>
const foo = document.querySelector('#foo')
const fooShadowDom = foo.attachShadow({ mode: "open"})
// 仅显示 abc
// fooShadowDom.innerHTML = `
// <div id="bar">
// abc
// </div>
// `
// 显示 abc,以及原元素中的内容
fooShadowDom.innerHTML = `
<div id="bar">
abc
<slot></slot>
</div>
`
</script>
上面使用的是匿名插槽,如果有多个插槽内容,可以使用命名插槽(named slot),类似 Vue 中的具名插槽
<div id="foo">
<div slot="a">我是a内容</div>
<div slot="b">我是b内容</div>
</div>
<script>
document.querySelector('#foo')
.attachShadow({ mode: "open"})
.innerHTML = `
内容b:
<slot name="b"></slot>
内容a:
<slot name="a"></slot>
`
// 内容b:
// 我是b内容
// 内容a:
// 我是a内容
</script>
影子 DOM 中的事件,如果影子 DOM 中发生了浏览器事件比如 click,事件会逃出影子 DOM 并经过事件重定向(event target)在外部被处理。
<div onclick="console.log('在外部处理', event.target)"></div>
<script>
document.querySelector('div')
.attachShadow({mode: 'open'})
.innerHTML = `
<button onclick="console.log('在内部处理', event.target)">Foo</button>
`
// 在内部处理 <button onclick="console.log('在内部处理', event.target)">Foo</button>
// 在外部处理 <div onclick="console.log('在外部处理', event.target)">…</div>
</script>
# 自定义元素
类似子框架中的自定义组件,比如 <my-button />,创建自定义元素有两种方法:
- 直接在 html 中写自定义元素,比如
<x-foo>我是自定义元素</x-foo> - 使用
customeElements.define(tagName, HTMLElementSubClass[, options])创建自定义元素
<x-foo>我是自定义元素</x-foo>
<script>
let xfooElement = document.querySelector('x-foo')
console.log(xfooElement instanceof HTMLElement) // true
</script>
使用 JS 创建自定义元素,下面的例子中,console 中会打印 3 个 hello,页面上 body 中会包含 3 个自定义元素
<div>1212</div>
<script>
class FooElement extends HTMLElement {
constructor() {
super()
console.log('hello')
}
}
customElements.define('x-foo', FooElement);
document.body.innerHTML = `
<x-foo>a</x-foo>
<x-foo>b</x-foo>
<x-foo>c</x-foo>
`
</script>
可以使用 customElements.define() 方法的第三个参数,可以标签(元素)指定为自定义元素的实例。注意自定义 FooElement 继承自 HTMLDivElement
<div>1212</div>
<script>
class FooElement extends HTMLDivElement {
constructor() {
super()
console.log('hello')
}
}
customElements.define('x-foo', FooElement, { extends: 'div' });
document.body.innerHTML = `
<div is="x-foo">a</div>
<div is="x-foo">b</div>
<div is="x-foo">c</div>
`
</script>
<!--
hello
hello
hello
-->
可以结合影子 DOM 向自定义元素添加内容
<div>123</div>
<script>
class FooElement extends HTMLElement {
constructor() {
super()
this.attachShadow({ mode: 'open' })
this.shadowRoot.innerHTML = `
<p>我是自定义组件的内容</p>
<slot></slot>
`
}
}
customElements.define('x-foo', FooElement)
document.body.innerHTML = `
<x-foo>
<div>我是插槽内容</div>
</x-foo>
`
// 我是自定义组件的内容
// 我是插槽内容
</script>
可以使用 template 重构上面的例子
<div>123</div>
<template id="x-foo-tpl">
<p>我是自定义组件的内容</p>
<slot></slot>
<style>
p { color: red }
</style>
</template>
<script>
const template = document.querySelector('#x-foo-tpl')
class FooElement extends HTMLElement {
constructor() {
super()
this.attachShadow({ mode: 'open' })
this.shadowRoot.appendChild(template.content.cloneNode(true))
}
}
customElements.define('x-foo', FooElement)
document.body.innerHTML += `
<x-foo>
<p>我是插槽内容</p>
</x-foo>
`
// 123
// 我是自定义组件的内容 // 红色
// 我是插槽内容 // 黑色 slot 内的内容不受影子 dom 内部样式影响
</script>
自定义元素有 5 个生命周期方法
- constructor() 在创建元素实例或将已有 DOM 元素升级为自定义元素时调用。
- connectedCallback() 在每次将这个自定义元素实例添加到 DOM 中时调用。
- disconnectedCallback() 在每次将这个自定义元素实例从 DOM 中移除时调用。
- attributeChangeCallback() 自定义元素可观察属性 的值发生变化时调用。在初始化值时,也算一次变化。
- adoptedCallback() 在通过 document.adoptNode() 将这个自定义元素移动到新文档对象时调用。
<div>123</div>
<script>
class FooElement extends HTMLElement {
constructor() {
super()
console.log('constructor')
}
connectedCallback() {
console.log('connected')
}
disconnectedCallback() {
console.log('disconnected')
}
}
customElements.define('x-foo', FooElement)
const fooElement = document.createElement('x-foo')
// constructor
document.body.appendChild(fooElement)
// connected
document.body.removeChild(fooElement)
// disconnected
</script>
observedAttributes() 方法可以定义改变时触发 attributeChangedCallback() 的属性名。下面是一个例子
<div>123</div>
<script>
class FooElement extends HTMLElement {
get bar() {
return this.getAttribute('bar')
}
set bar(value) {
return this.setAttribute('bar', value)
}
// 可观察属性 bar
static get observedAttributes() {
return ['bar']
}
attributeChangedCallback(name, oldValue, newValue) {
if (oldValue !== newValue) {
console.log(`oldValue: ${oldValue} => newValue: ${newValue}`)
this[name] = newValue
}
}
}
customElements.define('x-foo', FooElement)
document.body.innerHTML = `<x-foo bar="false">abc</x-foo>`
// oldValue: null => newValue: false
document.querySelector('x-foo').setAttribute('bar', 'true')
// oldValue: false => newValue: true
</script>
自定义元素 customElements 除了 define() 外,还有另外几个函数
customElements.whenDefined(tagName)返回 promise,当定义后触发 resolve 函数customElements.get(tagName)返回该自定义元素对应的构造函数(类 class)customElements.upgrade(customElement)强制升级自定义元素
<script>
customElements.whenDefined('x-foo').then(() => console.log('defined'))
console.log(customElements.get('x-foo')) // undefined
customElements.define('x-foo', class {}) // defined!
console.log(customElements.get('x-foo')) // class {}
</script>
当自定义元素没有创建时,也可以先创建该自定义元素,后面再使用 customElements.upgrade() 强制升级。
<script>
// 在自定义元素没有定义之前会创建 hTMLUnkownElement 对象
const fooElement = document.createElement('x-foo')
// 创建自定义元素
class FooElement extends HTMLElement {}
customElements.define('x-foo', FooElement)
console.log(fooElement instanceof FooElement) // false
// 强制升级
customElements.upgrade(fooElement)
console.log(fooElement instanceof FooElement) // true
</script>
# Web Cryptography API
Web Cryptography API 描述了一套密码学工具,规范了 JS 如果以安全和符合惯例的方式实现加密。包括生成、使用加密秘钥对,加密、解密信息以及生成可靠的随机数。
# 生成随机数
一般我们生成随机数首先想到的是 Math.random(),这个方法在浏览器中是以 伪随机数生成器(PRNG, PseudoRandom Number Generator) 方式实现的。pseudo- [ˈsuːdəʊ] 假的。伪随机指的是只是模拟了随机的特性,并未使用真正的随机源。如果使用 PRNG 生成的私有秘钥用于加密,攻击者可以利用它的缺点推算出私有秘钥。详情参见 p663
伪随机数生成器主要用于快速计算出看起来随机的值,并不适合用于加密计算。为了解决这个问题,引入了 CSPRNG(密码学安全伪随机数,Cryptographically Secure PseudoRandom Number Generator) 额外增加了一个熵作为输入。这样一来计算速度明显比 PRNG 慢很多,但 CSPRNG 生成的值很难预测,可以用于加密。
Web Cryptography API 引入了 CSPRNG,可以通过 crypto.getRandomValues() 访问 ,crypto [ˈkrɪptəʊ] graphy ['ɡræfɪ]。该函数会把随机值写入作为参数的定型数组,定型数组类型不重要,底层缓冲区会被随机的二进制位填充
// 定义 1 个字节的 typed array,最大值 255
const array = new Uint8Array(1)
for (let i = 0; i < 5; i++) {
let n = crypto.getRandomValues(array)
console.log(n, n[0])
}
// Uint8Array [140] 140
// Uint8Array [214] 214
// Uint8Array [122] 122
// Uint8Array [202] 202
// Uint8Array [81] 81
getRandomValues() 最多可以生成 2 ** 16(65536)字节,超出则会抛出错误 Failed to execute 'getRandomValues' on 'Crypto': The ArrayBufferView's byte length (65537) exceeds the number of bytes of entropy available via this API (65536).
const array = new Uint8Array(2 ** 16)
console.log(window.crypto.getRandomValues(array))
// Uint8Array(65536) [48, 96, 106, 4, 11, 72 186, 93, 44, 176, 156, 55, 178, 49, 255, 18, 173, 40, 193, 49, 3, 61, 194, 132, 190, 86, …]
const array2 = new Uint8Array(2 ** 16 + 1)
console.log(window.crypto.getRandomValues(array2))
// Uncaught DOMException: Failed to execute 'getRandomValues' on 'Crypto': The ArrayBufferView's byte length (65537) exceeds the number of bytes of entropy available via this API (65536).
使用 CSPRNG 重新视线 Math.random() 通过随机生成一个随机的 32 位数值,然后用他去除以最大的值 0xFFFFFFFF ,这样就会获得一个介于 0 和 1 之间的数
function randomFloat() {
const array = new Uint32Array(1)
// 0xFFFFFFFF === 2 ** 32 -1 // true
const maxUint32 = 0xFFFFFFFF
return crypto.getRandomValues(array)[0] / maxUint32
}
randomFloat()
// 0.2779637703853575
randomFloat()
// 0.21668057078883995
randomFloat()
// 0.8739860593047892
# SubtleCrypto 对象
subtle [ˈsʌtl] 精细的,Web Cryptography API 核心的特性都暴露在了 SubtleCrypto 对象上,可以使用 window.crypto.subtle 方法
console.log(crypto.subtle) // SubtleCrypto {}
可以用于加密、散列、签名和生成秘钥。由于所有密码学操作都在原始的二进制数据上执行,所以 SubtleCrypto 的每个方法都要用到 ArrayBuffer 和 ArrayBufferView 类型。由于字符串是密码学操作的重要场景,因此用于二进制数据与字符串之间相互转换的 TextEncoder 和 TextDecoder 经常与 SubtleCrypto 一起使用。
WARNING
SubtleCrypto 对象只能在安全的上下文(https)中使用,不安全的上下文中,crypto.subtle 属性为 undefined
# 生成密码学摘要(crypto.subtle.digest())
digest
[dɪˈdʒɛst]消化/摘要、hash[hæʃ]哈希/散列、algorithm[ˈæl ɡə rɪðəm]算法、Secure[sɪˈkjʊər]adj. 安全的
crypto.subtle.digest(hash(散列)算法类型, typedArray) 用于生成消息摘要,支持 4 种摘要算法:SHA-1 和 3 种 SHA-2,分别对应字符串 "SHA-1"、"SHA-256"、"SHA-384"、"SHA-512"。
SHA-1(Secure Hash Algorithm 1)构架类似 MD5 的散列函数。接收任意大小的输入,生成 160 位消息散列。容易受到碰撞攻击,该算法已经不再安全。SHA-2(Secure Hash Algorithm 2)构建于相同耐碰撞单向压缩函数之上的一套散列函数。规范支持其中三种 SHA-256、SHA-384、SHA-512。生成的摘要信息可以是 256位、384位、512位。该算法被认为是安全的,广泛应用于很多领域和协议,包括 TLS、PGP 和加密货币(如比特币)。
(async function () {
const textEncoder = new TextEncoder()
const msg = textEncoder.encode('foo') // Uint8Array(3) [102, 111, 111]
const msgDigest = await crypto.subtle.digest('SHA-256', msg)
console.log(msgDigest) // ArrayBuffer(32)
console.log(new Uint32Array(msgDigest))
// Uint32Array(8)
// [1806968364, 2412183400, 1011194873, 876687389,
// 1882014227, 2696905572, 2287897337, 2934400610]
})()
通常在使用时,二进制的消息摘要需要转换为 16 进制的字符串格式,256 位转 16 进制就是 64 位字符串。将二进制数据按照 8 位进行分割,再通过 toString(16) 就可以把任何数组缓冲区转换为 16 进制字符串
(async function () {
const textEncoder = new TextEncoder()
const msg = textEncoder.encode('foo') // Uint8Array(3) [102, 111, 111]
const msgDigest = await crypto.subtle.digest('SHA-256', msg)
console.log(msgDigest) // ArrayBuffer(32)
// 8位分割后的数据大小为 0 - 255
b = 44
b.toString(16) // "2c"
c = 1
c.toString(16) // "1"
c.toString(16).padStart(2, '0') // "01"
const hexDigest = Array.from(new Uint8Array(msgDigest))
.map(i => i.toString(16))
.join("")
console.log(hexDigest)
// 2c26b46b68ffc68ff99b453c1d30413413422d706483bfa0f98a5e886266e7ae
})()
在上面的例子中,把 new Uint8Array(msgDigest) 换成 16/32 位也可以生成字符串,就是和结果不一样,为什么一定要按照 8 位分割呢?二进制位以字节为单位?textEncoder.encode('foo') 默认编码后的就是 8 位?
计算文件的散列(hash)字符串,可以用于确认文件是否被修改过。例子参见 p665
# 根据秘钥算法生成秘钥(CryptoKey)实例(crypto.subtle.generateKey())
crypto.subtle.generateKey() 方法用于生成秘钥,返回一个 CryptoKey 实例。CryptoKey 类支持多种加密算法,允许控制秘钥抽取和使用。CryptoKey 类支持以下算法:
对称型加密算法(如 DES/AES 算法) 使用单个秘钥对数据进行加密或解密。非对称型加密算法(如 RSA 算法)也称为公用秘钥算法,有两个秘钥(公用秘钥和私用秘钥)。只有两者搭配才能完成加密或解密的全过程。
RSA(Rivest-Shamir-Adleman)1978年,麻省理工学院的三名教授瑞斯特(Rivest)、沙米尔(Shamir)和艾德曼(Adleman) 开发了非对称 RSA 公共密钥算法。公钥密码系统,使用两大素数获得一对公钥和私钥,可用于签名/验证或加密/解密消息。- 一些加密算法是对 RSA 的应用,比如:RSASSA-PKCS1-v1_5、RSA-PSS、RSA-OAEP
ECC(Elliptic-Curve Cryptography)公钥密码系统,椭圆曲线密码(Elliptic Curve[ɪ'lɪptɪk][kɜːv]),使用一个素数和一个椭圆曲线获得一对公钥和私钥,可用于签名/验证消息,ECC 被认为优与 RSA,它比 RSA 秘钥短,且操作更快。- 一些加密算法是对 ECC 的应用,比如:ECDSA、ECDH
AES(Advanced Encryption Standard)高级加密标准,属于对称秘钥密码系统。由于 DES 密钥太短已无法满足安全的需要,2000年10月美国国家标准与技术研究所(NIST)发布高级加密标准(AES)作为新的加密电子数据加密标准。使用派生自置换组合网络的分组密码加密和解密数据。AES 在不同模式下使用,不同模式算法的特性也不同。- AES 有多种模式的算法,比如:AES-CTR(AES 计数模式 counter mode)、AES-CBC(AED 密码分组链模式 cipher block chaining mode)、AES-GCM、AES-KW
HMAC(Hash-Based Message Authentication Code)哈希信息验证码, n. 认证 [ɔːˌθentɪˈkeɪʃn],用于生成消息认证码的算法,用于验证通过不可信网络接收的消息没有被修改过。两方使用hash函数和共享私钥来签名和验证消息。
TIP
上面只是列出部分,更多信息参见 p667。CryptoKey 支持很多算法,但其中只有部分算法可以用于 SubtleCrypto 的方法。如果需要了解细节,可以参考 W3C 上 Web Cryptography API 规范的 "Algorithm Overview"
crypto.subtle.generateKey(algorithm, extractable, keyUsages) 可以生成随机 CryptoKey,返回一个 Promise,resolve 是用来表示秘钥的一个或多个 CryptoKey 实例。它有三个参数:
algorithm指定加密算法类型的对象extractable[ɪk'stræktəbl]布尔值,表示密码是否可以从 CryptoKey 中提取出来keyUsages表示这个秘钥可以与那些 SubtleCrypto 方法一起使用,类型为字符串数组,比如 "encrypt"、"decrypt"、"sign"、"verify"、"deriveKey"、"wrapKey" 等
更多细节可以参考:SubtleCrypto.generateKey() | MDN (opens new window)
const key = await crypto.subtle.generateKey(
{
name: "AES-CTR",
length: 128
},
false,
['encrypt', 'decrypt']
)
// CryptoKey {type: "secret", extractable: false, algorithm: {…}, usages: Array(2)}
const key2 = await crypto.subtle.generateKey(
{
name: "ECDSA",
namedCurve: 'P-256'
},
true,
['sign', 'verify']
)
// {publicKey: CryptoKey, privateKey: CryptoKey}
// privateKey: CryptoKey
// algorithm: {name: "ECDSA", namedCurve: "P-256"}
// extractable: true
// type: "private"
// usages: ["sign"]
// __proto__: CryptoKey
// publicKey: CryptoKey
// algorithm: {name: "ECDSA", namedCurve: "P-256"}
// extractable: true
// type: "public"
// usages: ["verify"]
# 导出和导入秘钥(crypto.subtle.exportKey/importKey())
如果秘钥是可以提取的,那么就可以在 CryptoKey 对象内部暴露秘钥原始的二进制内容。使用 exportKey() 可以获取秘钥
crypto.subtle.exportKey(keyFormat, key)将秘钥 key 使用 format 指定的格式导出。format 格式可以使 "raw"(未加工的,原始的)、"pkcs8"、"spki" 或 "jwk"。该方法返回一个 Promise,resolve 一个包含秘钥的 ArrayBuffer 数组。crypto.subtle.importKey(keyFormat, keyData, algorithmName, extractable, keyUsages)将导出来的秘钥导入到一个新的秘钥对象中,相当于 generateKey() 和 exportKey() 的逆向操作。keyData 是使用 exportKey 导出的秘钥数据,algorithmName 是加密算法名称, extractable, keyUsages 参数同 generateKey() 函数。
(async function() {
const key = await crypto.subtle.generateKey(
{
name: "AES-CTR",
length: 128
},
true,
['encrypt', 'decrypt']
)
const rawKey = await crypto.subtle.exportKey('raw', key)
console.log(rawKey) // ArrayBuffer(16) {}
console.log(new Uint8Array(rawKey))
// Uint8Array(16) [126, 188, 169, 122, 134, 143, 90, 180, 153, 154, 133, 178, 133, 48, 217, 170]
let importedKey = await crypto.subtle.importKey('raw', rawKey, 'AES-CTR', true, ['encrypt', 'decrypt'])
console.log(importedKey)
// CryptoKey {type: "secret", extractable: true, algorithm: {…}, usages: Array(2)}
})()
# 从主秘钥派生秘钥(crypto.subtle.deriveKey/deriveBits())
derive [dɪˈraɪv] 派生,从已有秘钥获取新秘钥
crypto.subtle.deriveBits(algorithm, baseKey, length)返回一个 resolve 为 ArrayBuffer 的 Promise。crypto.subtle.deriveKey(algorithm, baseKey, derivedKeyAlgorithm, extractable, keyUsages)返回一个 resolve 为 CryptoKey 的 Promise。与调用 deriveBits() 后再将结果传给 importKey() 结果相同。
const keyA = await crypto.subtle.generateKey({
name: 'ECDH',
namedCurve: 'P-256'
}, true, ['deriveBits'])
const keyB = await crypto.subtle.generateKey({
name: 'ECDH',
namedCurve: 'P-256'
}, true, ['deriveBits'])
const deriveAB = await crypto.subtle.deriveBits({
name: 'ECDH',
namedCurve: 'P-256',
public: keyA.publicKey // A 的公钥
}, keyB.privateKey, 128) // B 的私钥
// ArrayBuffer(16) {}
const deriveBA = await crypto.subtle.deriveBits({
name: 'ECDH',
namedCurve: 'P-256',
public: keyB.publicKey // B 的公钥
}, keyA.privateKey, 128) // A 的私钥
// ArrayBuffer(16) {}
const arrayAB = new Uint32Array(deriveAB)
const arrayBA = new Uint32Array(deriveBA)
console.log(deriveAB, deriveBA, arrayAB, arrayBA)
// ArrayBuffer(16) {}
// ArrayBuffer(16) {}
// Uint32Array(4) [434851524, 2869415471, 310093849, 3098225050]
// Uint32Array(4) [434851524, 2869415471, 310093849, 3098225050]
deriveKey 实例参见 p671
# 使用非对称秘钥签名和验证消息(crypto.subtle.sign/verify())
一般使用私钥生成签名,对应 sign() 方法。使用公钥验证签名,对应 verify()。
(async function() {
const { publicKey, privateKey } = await crypto.subtle.generateKey({
name: 'ECDSA',
namedCurve: 'P-256'
}, true, ['sign', 'verify'])
// 使用私钥生成签名
const msg = (new TextEncoder()).encode("some info, some msg")
const signature = await crypto.subtle.sign({
name: 'ECDSA',
hash: 'SHA-256'
}, privateKey, msg)
console.log(signature) // ArrayBuffer(64) {}
console.log(new Uint32Array(signature))
// Uint32Array(16) [965020713, 1414793526, 3039910164, 2277130781, ...]
// 使用公钥验证消息是否正确
const verified = await crypto.subtle.verify({
name: 'ECDSA',
hash: 'SHA-256'
}, publicKey, signature, msg)
console.log(verified) // true
})()
# 使用对称秘钥加密和解密(crypto.subtle.encrypt/descrypt())
(async function() {
const key = await crypto.subtle.generateKey({
name: 'AES-CBC',
length: 256
}, true, ['encrypt', 'decrypt'])
const originalPlainText = (new TextEncoder()).encode("some info, some msg")
// cipher [ˈsaɪfər] 密码
// 加密信息
const params = {
name: 'AES-CBC',
iv: crypto.getRandomValues(new Uint8Array(16))
}
const cipherText = await crypto.subtle.encrypt(params, key, originalPlainText)
console.log(cipherText) // ArrayBuffer(32) {}
// 解密信息
const decryptedPlainText = await crypto.subtle.decrypt(params, key, cipherText)
console.log(decryptedPlainText) // ArrayBuffer(19) {}
console.log((new TextDecoder()).decode(decryptedPlainText))
// some info, some msg
})()
# 包装和解包秘钥(crypto.subtle.wrapKey/unwrapKey())
SubtleCrypto 支持包装(wrap)与解包(unwrap)秘钥,以便在非信任渠道传输信息,分别对应 crypto.subtle.wrapKey() 与 crypto.subtle.unwrapKey(),来看一个例子,生成对称 AES-GCM 秘钥,用 AES-KW 来包装秘钥,再解包
(async function() {
// 对称 AES-GCM 秘钥
const key = await crypto.subtle.generateKey({
name: 'AES-GCM',
length: 256
}, true, ['encrypt'])
// 用于包装秘钥的 AES-KW 秘钥
const wrapKey = await crypto.subtle.generateKey({
name: 'AES-KW',
length: 256
}, true, ['wrapKey', 'unwrapKey'])
// 包装后的秘钥
const wrappedKey = await crypto.subtle.wrapKey('raw', key, wrapKey, 'AES-KW')
console.log(wrappedKey) // ArrayBuffer(40) {}
// 解包后的秘钥
const unwrappedKey = await crypto.subtle.unwrapKey('raw', wrappedKey, wrapKey, {
name: 'AES-KW',
length: 256
}, {
name: 'AES-GCM',
length: 256
}, true, ['encrypt'])
console.log(unwrappedKey)
// CryptoKey {type: "secret", extractable: true, algorithm: {…}, usages: Array(1)}
})()